Evaluation of Similarity-based Explanations
reading papers
どんなものか
説明性aiの手法の一つにモデルの予測の際に訓練データの中から類似のインスタンスを提供する方法がある。この類似を測るためにいくつかのrelevance metricsがある。本研究ではユーザーに合理的な説明を行うことができるrelevance metricsの検討をおこなった。
技術や手法のポイント
類似性ベースの説明のために望ましい性質を持つrelevance metricsを3つのテストにより評価した。
-
モデル無作為化テスト
訓練されたモデルとランダムな重みのモデルが同じ説明を行うとき、その指標はモデルを無視しており信用ならない
-
同一クラステスト
説明したいインスタンスと説明として示すインスタンスのクラスが違うと説明として意味不明になってしまう

-
同一サブクラステスト
クラスが潜在的なサブクラスから構成されている場合、上げられた類似インスタンスはテストインスタンスと同じサブクラスに属するべきである

検証方法
実験は2つの画像データセット(MNIST, CIFAR10), 2つのテキストデータセット(TREC, AGNews), 2つの表データセット(Vehicle, Segment)を用いた。
論文では主にCNNを用いたCIFAR10とBi-LSTMを用いたAGNewsの結果について紹介されている。ここではCIFAR10を用いる。
モデルはMobileNetV2を使用する。
実験手順はモデルの訓練、ランダムな500個のテストインスタンスの抽出、3つのテストの流れを10回繰り返した。それぞれのテストは定量的に評価を行う。
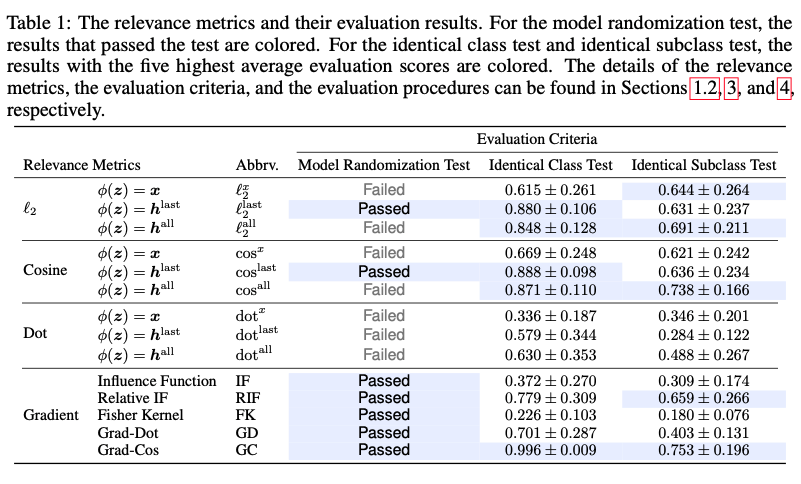
結果のまとめの表 GCが一番良い結果となっている
議論
今回のテストはrelevance metricsの忠実性と妥当性の限られた側面を評価したに過ぎず、より詳細な評価を行うために更なる基準を検討する必要がある。(今回の評価だけでは十分でない)
また類似度に基づく説明だけでなく、反例など他の説明手法の評価についても検討する必要がある。
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025