Towards Automatic Concept-based Explanations
reading papers
どんなものか
データセット全体に適用される視覚的概念を自動的に抽出するACE(Automated Concept-based Explanations)という手法を開発した。
先行研究と比べて
従来の手法では概念を人間の手によってラベル付けしていたが、問題点として可能な概念の空間が無限んであったり人間のバイアスに依存することがあげられる。この部分を概念が満たすべき一般原則をあげた上で自動化させることで解消させた。
技術や手法のポイント
概念を基にした説明手法に望まれる性質として
- 意味性:概念の一例がそれ自体で意味を持っている
- 一貫性:ある概念の例は知覚的に互いに類似しているが、他の概念の例とは異なっている
- 重要性:あるクラスの予測においてそのクラスのサンプルを正しく予測するためにその概念の存在が必要である場合その概念は重要である
の3つをあげている。
ACEは学習済みの分類器とあるクラスの画像群を入力として、そのクラスに存在する概念を抽出し各概念の重要度を返す。
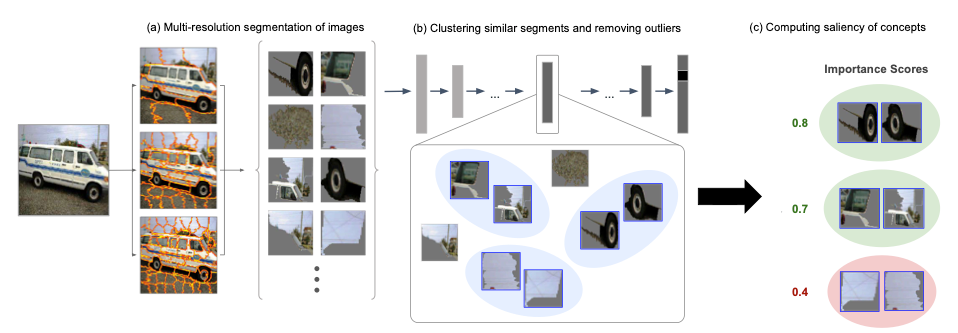
fig 1: (a) 同じクラスからの画像のセットが与えられる。各画像は複数の解像度で分割され、その結果、すべて同じクラスからのセグメントからなるプールが形成される。(b) 最先端のCNN分類器の1つのボトルネック層の活性化空間が類似性空間として使用される。各セグメントをモデルの標準入力サイズにリサイズした後、類似セグメントは活性化空間においてクラスタ化され、クラスタの一貫性を高めるために外れ値が除去される。(d) 各概念について、その例となるセグメントから TCAV 重要度スコアが計算される。
方法としては
- 与えられたクラス画像のセグメンテーションを行う
- 類似するセグメントを同じ概念の例としてグループ化する
- 概念の集合からクラスに対して重要な概念を返す
検証方法
ImageNetデータセットに対し100クラスのサブセットを選択しACEを適用した。モデルはInception-V3モデルを使用した。

fig 2: ここでは、各クラスの上位4つの重要な概念をランダムに選択した3つの例を示しています(各例は、セグメント化された元の画像の上に表示されています)。この結果から、例えば、バンのタイヤと警察のロゴを使用して、ネットワークが警察のバンを分類していることがわかります。
図2ではACEを適用した例を示す。3つのクラスについて最も重要な4つの概念をランダムに選んだ3つの例画像に対して示す。
概念の一貫性や人間にとって意味のある概念になっているかを調べるためアンケートを用いた実験を行なった。
議論
本手法では概念はピクセルのグループとして現れるものにのみ適用される。
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025