Sanity Checks for Saliency Maps
reading papers
どんなものか
説明手法としていくつかのsaliency maps手法が提案されてきた。本研究ではsaliency maps手法を評価するための実用的な方法論を提案する。
先行研究と比べて
多くのsaliency maps手法はその評価をすることの難しさという方法論的な課題に直面している。そこで与えられたタスクに対する説明手法の適切性を評価するテストを提案する。
技術や手法のポイント
- モデルパラメータ無作為化テスト(The model parameter randomization test)
学習済みモデルに対するsaliency mapsの出力と、同じモデルのランダムに初期化されたネットワークに対するsaliency mapsの出力を比較することで評価を行う。もしモデルのパラメータに依存するなら出力は大きく異なることが予想される。
- データランダマイゼーションテスト(The data randomization test)
ラベル付けされたデータセットで学習させたモデルのsaliency mapsの出力と、ランダムにラベル付けされたモデルでのsaliency mapsの出力を比較することで評価を行う。もしデータとラベルに依存していた場合、出力は大きく異なることが予想される。
検証方法
- モデルパラメータ無作為化テスト
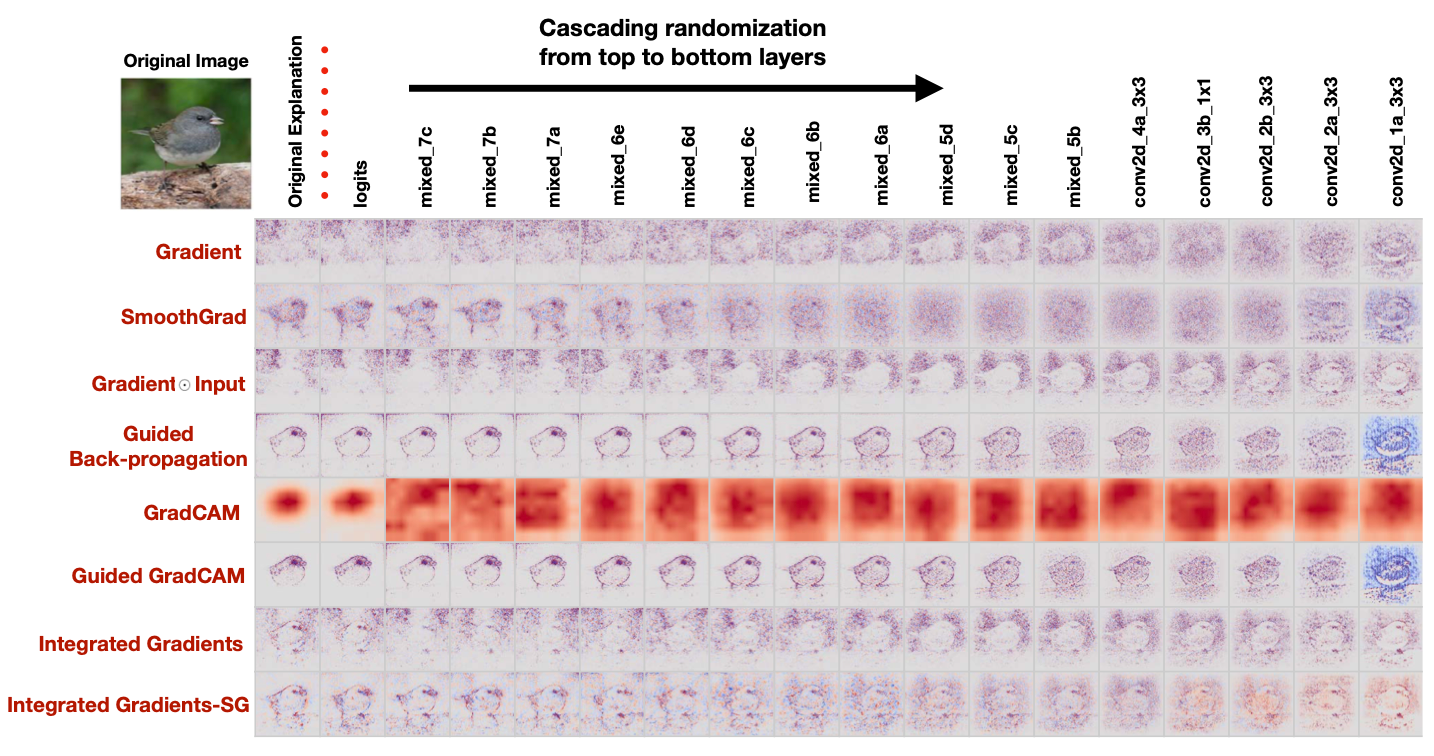
Inception v3(ImageNet)におけるCascading randomization。図は、Junco鳥の元の説明(最初の列)と、各説明タイプのラベルを示す。左から右への進行は、その「ブロック」を含むまでのネットワーク重み(および他の学習可能な変数)の完全なランダム化を示す。17ブロックのランダム化の画像を示す。Coordinate (Gradient, mixed_7b) は、Logitsから始まってmixed_7bまでの最上位層を再初期化したネットワークの勾配説明を示しています。最後の列は、重みが完全に再初期化されたネットワークに対応する。
上位層から順にパラメータをランダム化してsaliency mapsの出力を比較したもの。
Guided BackpropやGradientではランダムな重みでもあまり出力が変わらないことが見て取れる。
- データランダマイゼーションテスト
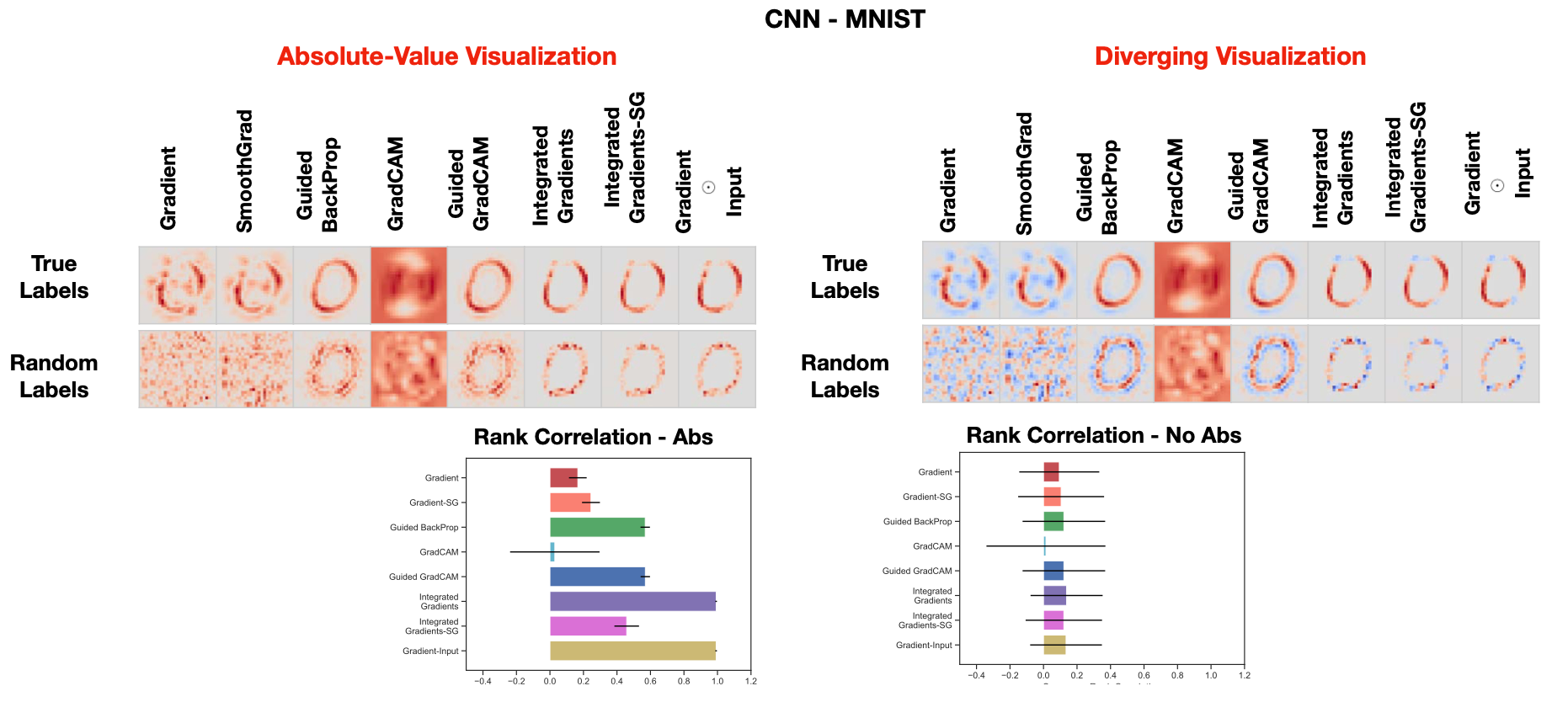
図6:真のモデルとランダムラベルで学習したモデルの比較説明。左上:MNISTテストセットの数字0のマスクの絶対値をCNNで可視化したもの。右上: MNISTのテストセットから得られた0桁のCNN用顕著性マスクを発色させたもの。左下:顕著性手法のスピアマン順位相関(絶対値付き)棒グラフ。ランダムなラベルで学習したモデルと、実際のラベルで学習したモデルから得られる説明の類似度を比較している。右下。MLPの顕著性手法のスピアマン順位相関(絶対値なし)棒グラフ。
MNISTデータセットに対してラベルをランダムにして学習をさせたもの。
議論
sanity checkをパスできないような手法は確かに論外な気もするが、ほとんどの手法は通り抜ける気がする。
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025