Masked Autoencoders Are Scalable Vision Learners
reading papers
どんなものか
- ViTバックボーンに対して性能の高い自己教師あり学習器を提案した
- masked autoencoderを用いて事前学習したモデルのencoder部分を使って学習させると非常に高い性能を出せることを示した
先行研究と比べて
- 自然言語処理分野における事前学習手法としてマスク処理の手法は大きな成功を収めている
- オートエンコーダは表現を学習する古典的な手法であり, 本手法では画像のマスキングを用いることで一般化されたDenosising autoencodersとして考えることができる
- 事故教師あり学習のアプローチはコンピュータビジョン分野で大きな関心を集めており, Contrastive Learning など様々な手法が提案されてきている
技術や手法のポイント
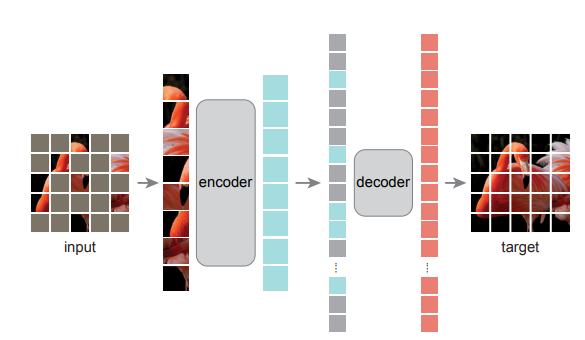
- 図はMAEモデルアーキテクチャ
- 画像の一部をマスクし, マスクされていない部分のみをEncoder Blockに入力、得られたトークンベクトルとマスクされた部分をマスクトークンとして合わせたものをデコーダー(ViTのEncoder Blockと中身は同じ)に入れ, トークンから元の画像サイズとなるような全結合層を通して画像を出力する
- MAE Decoder
- マスクトークンは学習可能なパラメータにより初期化(初期化の値が学習可能)
- 位置埋め込みは2次元sinusoidal positional embedding
- エンコーダよりもトークン次元数を少なく, 深さも小さめの全体として小さなデコーダーを用いている
- 学習時間削減が見込める
検証方法
- ベースライン
- ViT Largeのモデルを用いてmaeによるpretrain, imagenetによるfine tuningしたものをベースラインとする
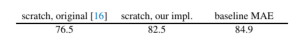
- 左からオリジナルのスクラッチ学習, ハイパラなど頑張って調整した著者スクラッチ学習, mae->finetuning, の精度
- アブリエーションスタディ
- fine-tuningとlinear probing(mlpヘッドの部分のみを使って再学習)を用いている
- mask ratio
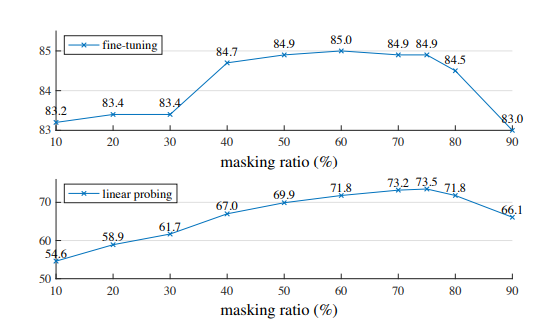
- 75%と高いほうが精度が出る結果となる
- 自然言語(BERTで15%)とは対照的である
- 高い削除率は線やテクスチャの延長線上のみで完結しない物体や情景のゲシュタルトを理解するものであり有用な表現の学習と関連していると仮定している
- デコーダーの設計
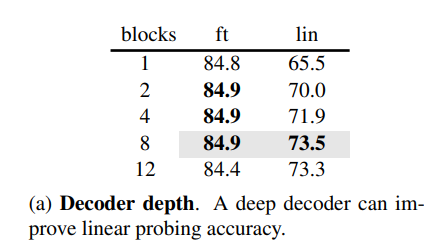
- デコーダーの深さはfine tuningにあまり影響しない
- これは画像認識においてはencoderが重要であり, Decoderは画像復元タスクの精度に影響すると考えられる
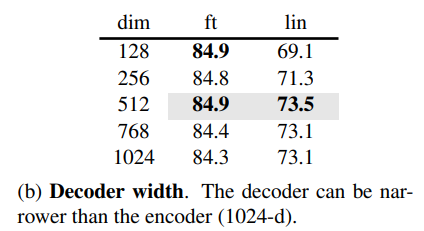
- デコーダーのトークンの長さもfine tuningの精度にはあまり影響しない
- エンコーダーでのマスクトークン

- 本アーキテクチャの特徴的な点としてマスクトークンをエンコーダ部分では入れずスキップさせている点がある
- マスクトークンは本来の画像にはないものであり, それがエンコーダー部分の学習に悪影響を与える可能性がある
- エンコーダーからマスクトークンを取り除くことで常にエンコーダーは実画像部分パッチを見ることになりその制約が精度を向上させている
- また学習速度向上, メモリ使用の削減にもなる
- 再構成損失
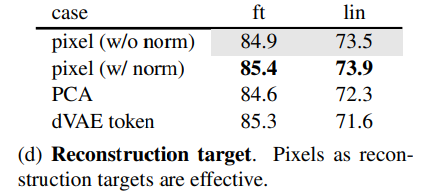
- 正規化ありのピクセル誤差が一番性能が良かった
- またほかの損失についてもみると高周波成分の損失を見れるほうが性能が良くなることが示唆される
- 訓練エポック
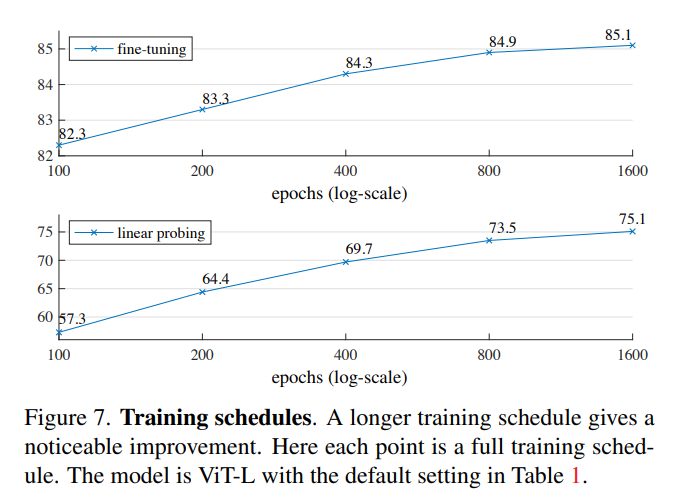
- 訓練時間が長いほど精度は着実に向上している
- 1600epochでも飽和していない
- 先行研究との比較
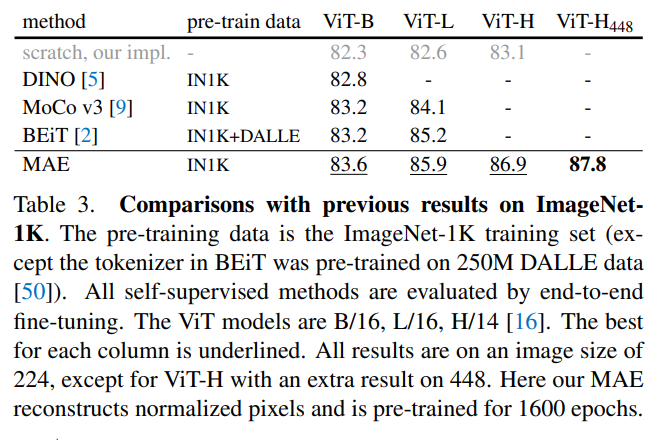
- 精度はもちろん、学習時間の面でもmaeは優れている
- 例えばViT-Lを128 TPU-v3コアで学習した場合maeは1600epochで31時間, MoCo V3は300epochで36時間かかった
議論
- スケーラビリティの高いシンプルなアルゴリズムにもかかわらず高い認識精度を達成できている
- 高いマスク率で複雑な再構成を行うことで多数の視覚的概念, 意味を学習したことが示唆される
*****
Non sunt multiplicanda entia sine necessitate
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025