learning transferable visual models from natural language supervision
reading papers
どんなものか
- Webで収集した4憶の画像とテキストのペアから、どの画像がどのキャプションに合うかを学習させると有効な画像表現が得られる
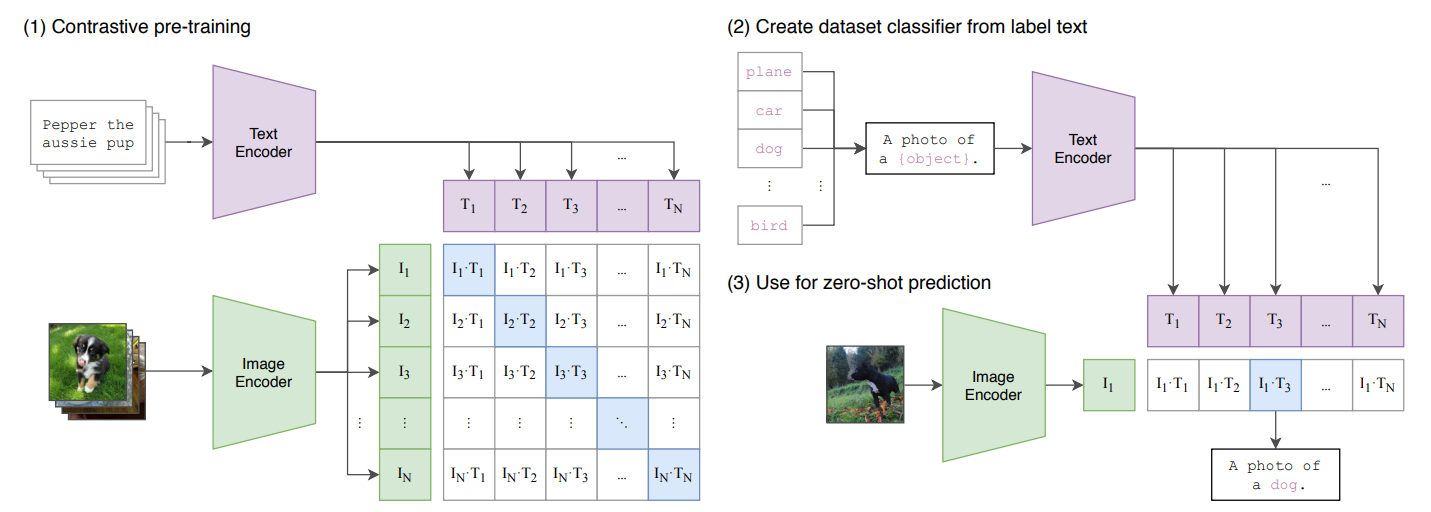
先行研究と比べて
- 自然言語を利用した画像分類器はいくつかあったが単純に精度が出てなかった
- また弱教師ありの形で補間するような学習を行う試みも行われてきたが柔軟性が低くスケール性能が低い問題点があった
技術や手法のポイント
- N個の画像-テキストペアが与えられるとN×N通りの組み合わせが考えられるが正しいペアのコサイン類似度を高め、違うペアのコサイン類似度を下げるように学習する
- 上記をスコアとしてクロスエントロピー損失を最適化する
- モデルアーキテクチャ
- 画像エンコーダとしてはResNetとViTの2種類を考え、テキストエンコーダとしてはTransformerを用いる
検証方法
- ゼロショットの精度について
- ResNet-50による完全教師あり学習と比較
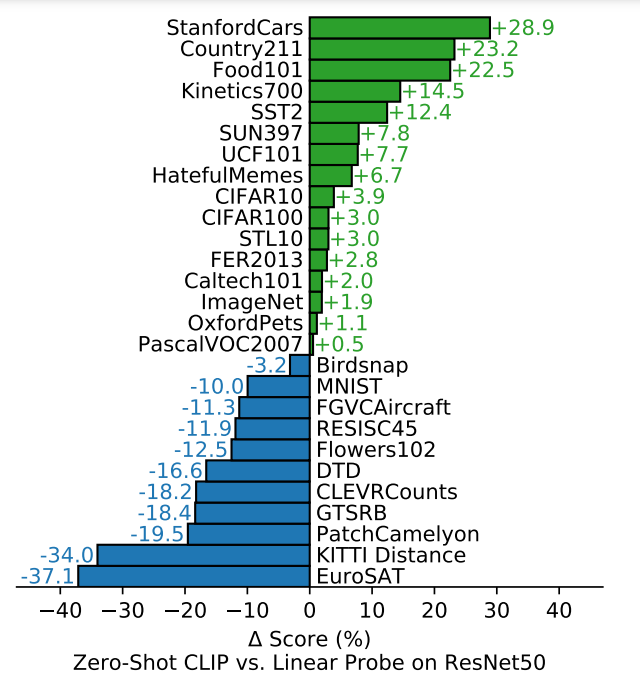
- 特徴として
- 動画データセットでも良い結果が得られた
- 特定の分野に特化したもの複雑なもの抽象的なものでは精度が出せなかった
- スケール性能、汎化性能について
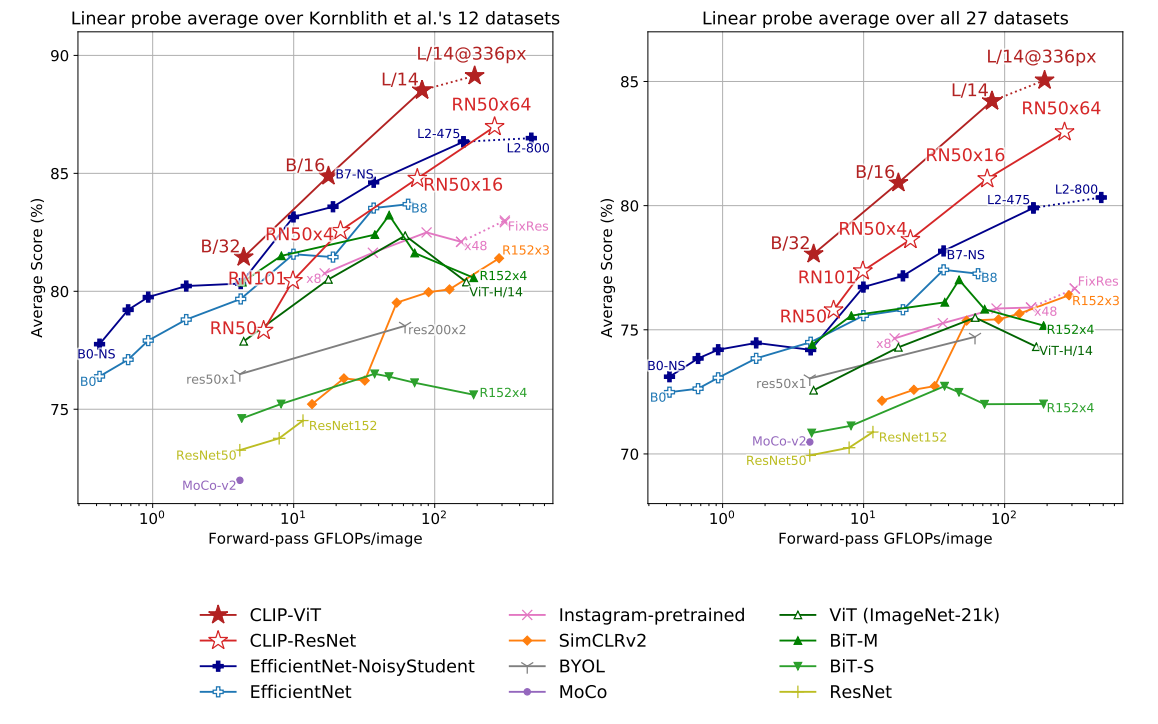
- 図は縦軸に12個のデータセットの平均スコアを横軸にモデルサイズをとったものである
- モデルを大きくするとCLIPはスケールすることが分かる
議論
*****
Non sunt multiplicanda entia sine necessitate
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025