Sparse and Hierarchical Masked Modeling for Convolutional Representation Learning
reading papers
どんなものか
- CNNベースのモデルに対してmasked image modelingを用いた事前学習における2つの重要な障害を特定し克服した
- 畳み込み演算は不規則でランダムなマスクの入力画像を扱えない
- BERT 事前学習のシングルスケールの性質はconvnetの階層的な構造と矛盾している
先行研究と比べて
- マスクされた部分の画素値を0としてCNNに送り込むこともできるが激しいデータ分布のずれなどが起こり MAE などと同様には上手くいかない
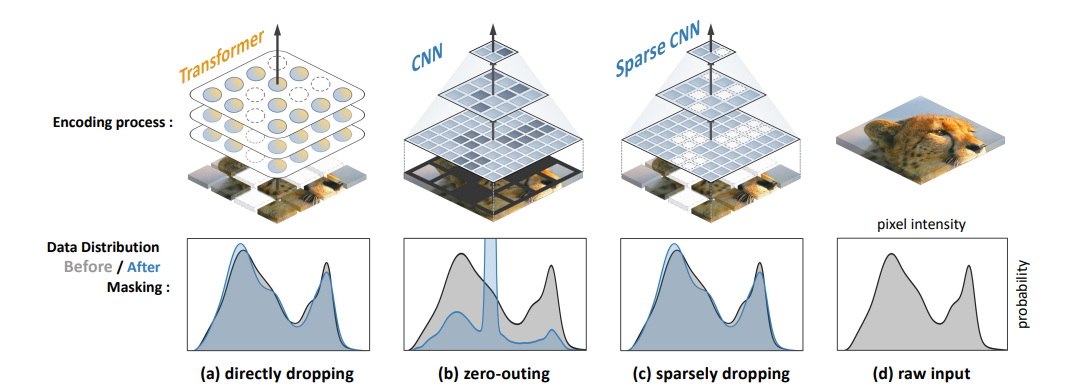
- また自然言語処理から着想を得たmaskではCNNの階層的な処理の利点が失われてしまう
技術や手法のポイント
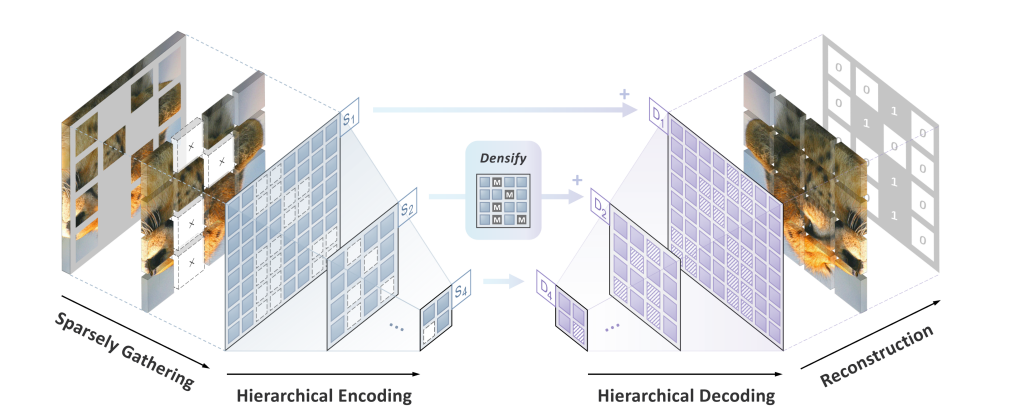
- 提案手法はSparse masKed modeling (SparK)と呼ばれ下図のような階層的マスクイメージモデリングによって畳み込みネットワークを事前学習させることを目的としている
- CNNでのmasked image modelingの欠点として下図の左にあるように密な畳み込みの計算によりフィルタが0でない点を少しでもカバーした瞬間にmaskされていた部分の結果が0でなくなってしまい、最終的にはマスク領域が消失する
- 数層畳み込みを行うとマスクされた部分がなくなってしまうのは望ましくない
- そこで疎な畳み込みを利用することでこの問題を解決する
- ここでの疎な畳み込みとはマスクされた領域はすべて計算上スキップしマスクされていない点のみで計算を行う
- これにより畳み込みによりマスクパターンの形状が変化するのを防げる
- デコードするためのモデルアーキテクチャとしては UNet を用いる

検証方法
- 下流タスクにおける精度で検証を行う
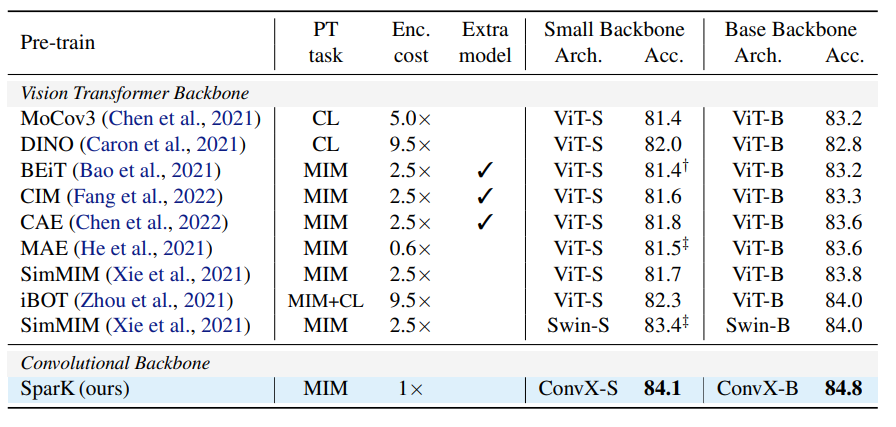
- ImageNetを用いてTransformerバックボーンに対して様々な事前学習を用いてImageNetでファインチューニングした時の精度との比較
- COCOデータセットによるセグメンテーションや物体検出タスクにおける比較
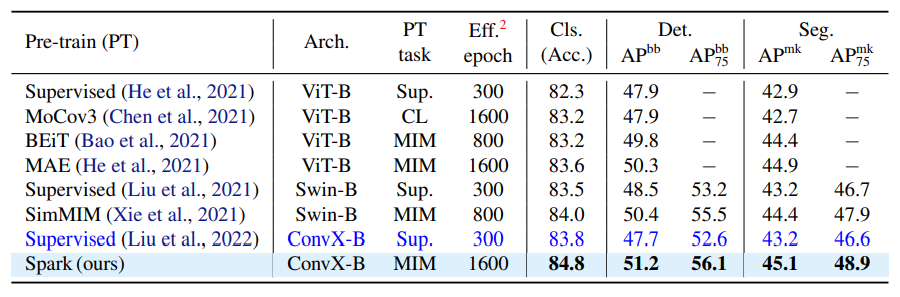
- SparKと対比系の事前学習手法の精度比較
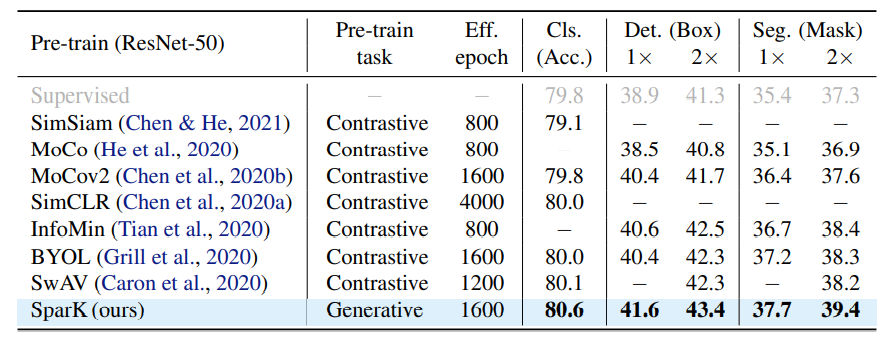
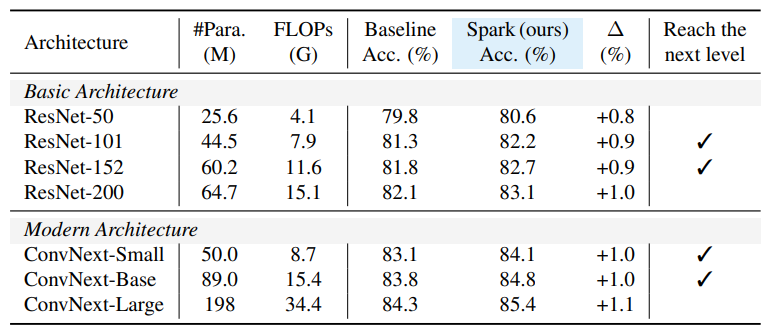
- スケールアップの確認
- 再構成結果の可視化
- マスク率は60%

議論
- CNN使ってるから再構成で高周波成分に強かったりとかあるんかな
*****
Non sunt multiplicanda entia sine necessitate
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025