Training language models to follow instructions with human feedback
reading papers
どんなものか
- 強化学習によるフィードバックを用いて言語モデルを人間の意図に沿うように調整する手法
- ラベラーが用意したプロンプトセットを教師ありで学習し、さらにそこから追加で人間からのフィードバックによる強化学習で調整を行う
- このモデルはInstructGPTと呼ぶ
先行研究と比べて
- RLHF (Reinforcement Learning from Human Feedback)
- 最近の研究で言語モデルをRLHFによってファインチューニングするものがたくさん出てきている
- 要約, 対話, 意味解析, ストーリー生成, レビュー生成, 証拠抽出など
- 特に文体継続と要約のドメインで適用した論文の方法論を本論文では踏襲している
- 最近の研究で言語モデルをRLHFによってファインチューニングするものがたくさん出てきている
- GPT-3
- GPT-3は次に来る単語の予測をすることで自然な文章を生成することはできるが, タスクの目的が違うので「ユーザーの指示に懇切かつ安全に従う」という目的は達成できない
- また意図しない行動を回避することはアプリケーションを考えると重要になってくる
技術や手法のポイント
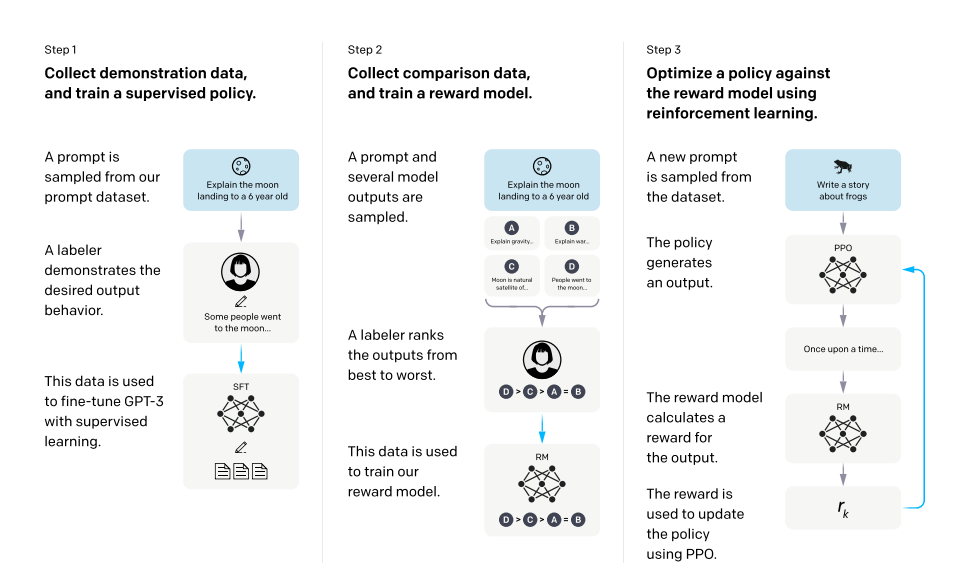
- 事前に学習した言語モデル(GPT-3), モデルがユーザーに沿った出力を生成させたいようなプロンプトの分布, 報酬ラベルを付ける人間のチームを用意し以下の3ステップを行う
- デモデータの収集と教師ありでの方策の学習
- ラベラーは入力プロンプト分布に対して, 望ましい動作のデモを作成する
- 比較データの収集と報酬モデルの学習
- ラベラーは与えられた入力に対して, どちらの出力を好むかを示す
- 人間が好む出力を予測する報酬モデルを学習する
- PPOにより報酬モデルに対する方策を最適化する
- デモデータの収集と教師ありでの方策の学習
- 教師付き調整
- GPTの出力に対して, ラベラーのデモを教師としてファインチューニングを行う
- 報酬モデル
- 上のモデルから最後の層を削除し, プロンプトと応答を入力としてスカラー報酬値を出力するモデルを訓練する
検証方法
- モデルは大きなブラックボックスであるので, 閉じた領域のタスクで情報を作り上げるモデルの傾向を評価する
- また公開データセット(TruthfulQAデータセット)も使用する
-
これらは真実性によって実際に意味されることのごく一部を捉えたに過ぎないが
- 人間にとって良い出力となっているか
- 教師あり調整を行ったところまでのモデル(SFT 175B)をベースラインとした
- ベースラインモデルとどちらがよりよい出力になっているかをwin rateの形で可視化したグラフとなっている
- 上下は実際に訓練を行った人による評価か訓練にはかかわらなかった人による評価である
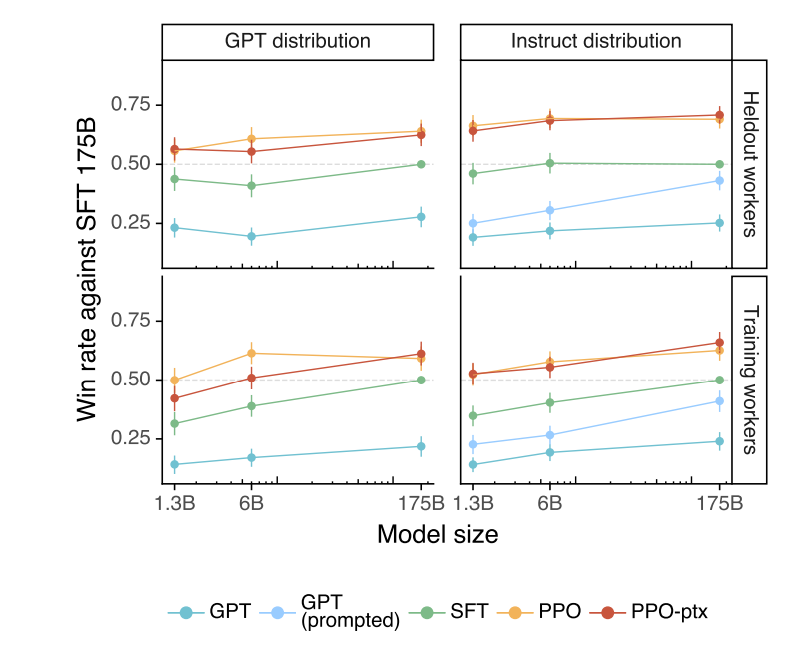
- 結果を見ると, 強化学習後のモデルはGPTのモデルサイズが小さいものでも有効な結果を出せていることが分かる
- 指示を守るかどうか
- より具体的な指示に対して従えているかどうかを評価したグラフ
- 左から順に, 正しい支持の施行が行えているか, 明示的な制約に従っているか, 嘘を作り上げたりしないかどうか, ユーザーの言語と同じ言語で返しているか
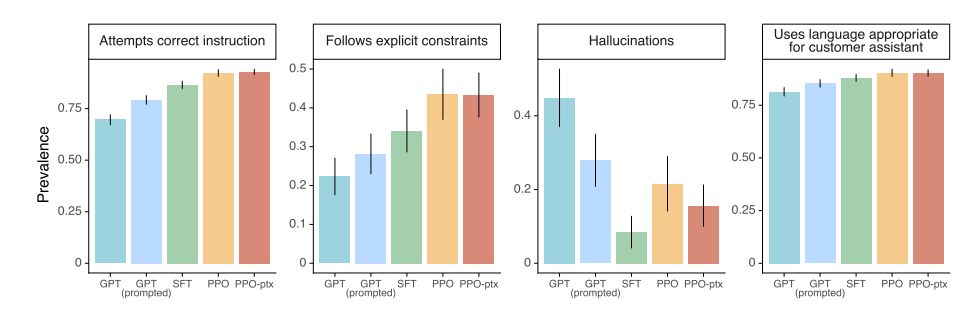
- 人のフィードバックが入るとそれっぽいことをいう方が良い結果になる
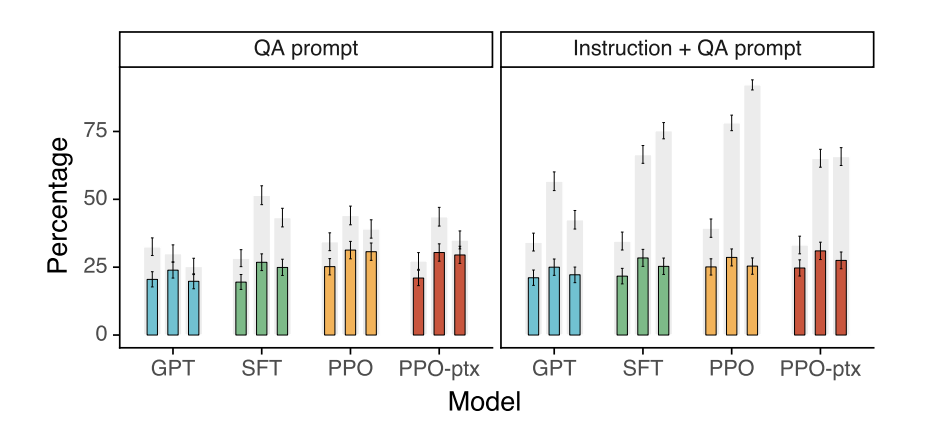
- TruthfulQA dataset
- NLPのオープンデータセットによる評価
- 確定した事実が存在するが, 誤った信念や誤解によって誤答するようなデータセット
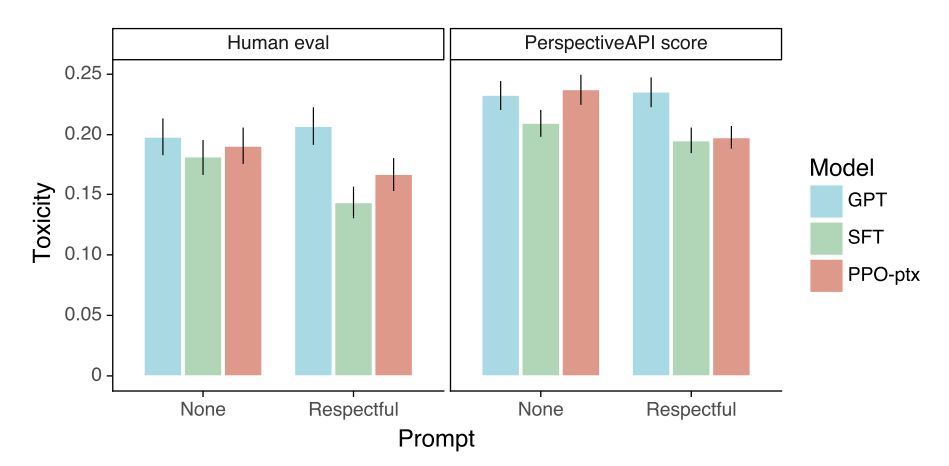
- RealToxicityPrompts
- NLPのオープンデータセットによる評価
- 有害性のない文章の一部分と, 有害性を判定するスコアのペアからなるデータセット
- 有害性のない文章に続いて有害な文を生成してしまうかどうかをみる
議論
- 依然として簡単なミスは残っている
- 誤った前提に基づく指示を入れると, その誤った内容をそのまま受け入れて出力する
*****
Non sunt multiplicanda entia sine necessitate
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025