Label Distribution Learning
reading papers
どんなものか
- マルチラベル学習が必要となるアプリケーションのためにLabel Distribution Learning(LDL) という新しい学習パラダイムを提案する
- そのうえで6つのKDKアルゴリズムを提案し評価を行う
- 評価を行うための指標も6つの尺度について提案した
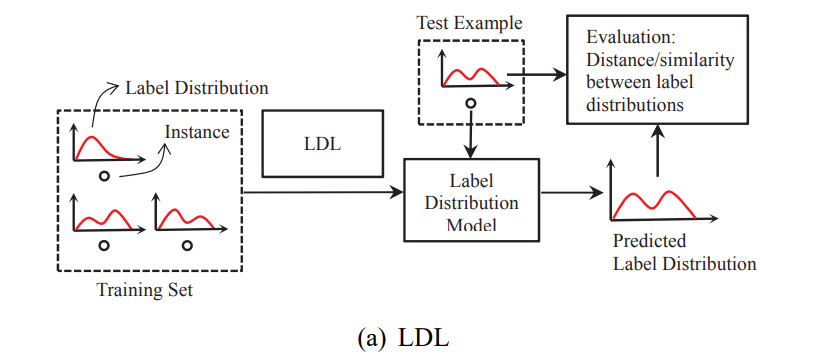
先行研究と比べて
- 既存のLDLでは
- 1つ以上のSingle Label Learning(SLL)に変換
- SLLを拡張してマルチラベルを扱う
- などがあるが提案手法では
- 単一のラベルやラベルセットではなく、ラベル分布を用いて学習をする
- ランキングなどの必要でないものを取り入れない学習ができる
- 従来手法ではランキング学習を取り入れてた
- という利点がある
技術や手法のポイント
- ラベル分布を学習させて、正解ラベル分布(クラス1,2,…nに対して(1), (1,2), (1,2,…,n)が正解の分布を考えるとn(n-1)パターンの分布が考えられる)と比較してテスト画像の分布がどのラベル分布と近いかで推論を行う
- アルゴリズム(モデル)は
- PT-Bayes, PT-SVM, AA-kNN, AA-BP, SA-IIS, SA-BFGS
検証方法
- モデルの出力は確率分布で、正解ラベルも分布である
- したがってしようとしては分布間の距離や類似度となるべきである
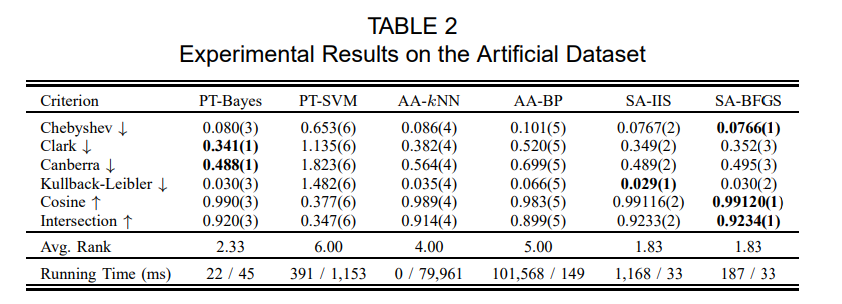
- 距離や類似度の中から性質の違うものを6つ選び実験を行った
-
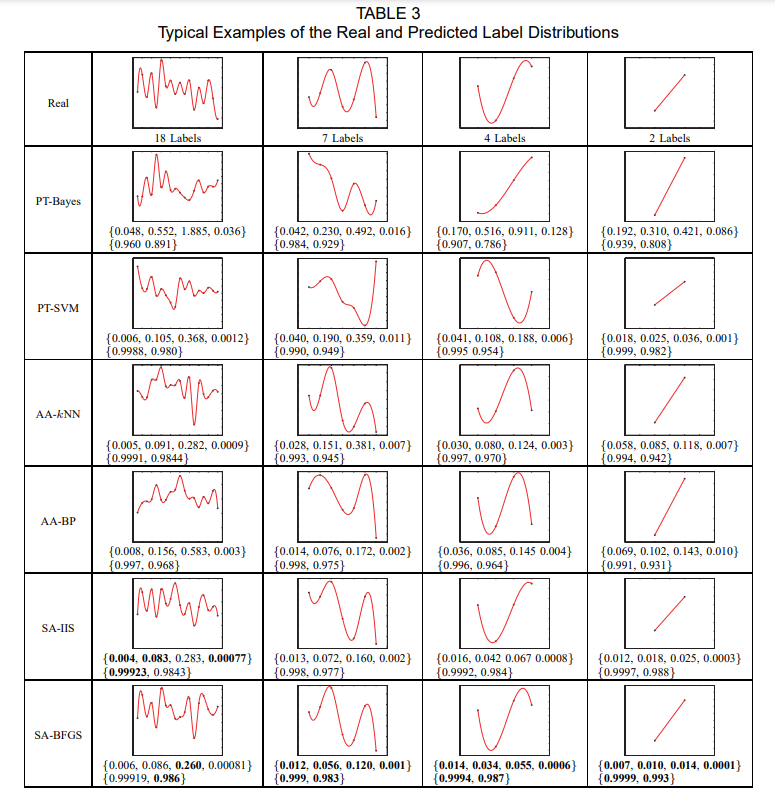
- 実ラベルの分布と予測したラベルの分布の例
-
- それぞれのアルゴリズムについての比較もあるが実験の表の数がものすごいので結論だけ
- 全距離指標を用いた実験において全てSA-BFGSが一番性能が良かった
議論
- 昔の論文過ぎて深層学習浸透前の論文だが、考え方は使えそう
*****
Non sunt multiplicanda entia sine necessitate
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025