HyperSTAR: Task-Aware Hyperparameters for Deep Networks
reading papers
どんなものか
- ハイパーパラメータ最適化は与えられたタスクに適応していない(task-agnostic)ため計算効率が悪い
- そこでデータセットとハイパーパラメータから性能の予測をし、ハイパーパラメータの候補にランク付けを行うモデルを提案した
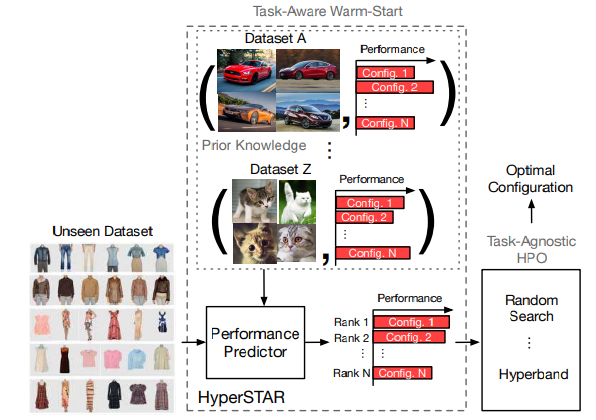
先行研究と比べて
- ランダム探索やベイズ最適化のアプローチは過去の経験からの情報を利用しないため、手動検索よりも効果的だが低速という問題が生じる
- タスクを理解するための画像特徴を使ってハイパーパラメータ最適化をウォームスタートさせる手法も提案されているが、タスクとハイパーパラメータの共同表現が欠如している
技術や手法のポイント
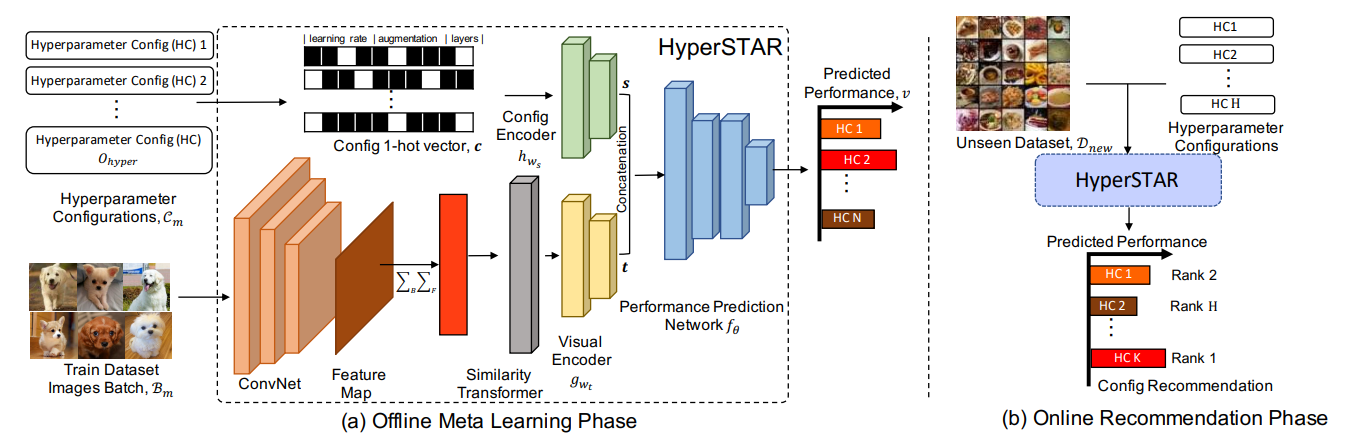
- (a)オフラインメタ学習フェーズ
- タスク表現とハイパーパラメータの符号化から性能を予測する回帰モデルを目標とする
- タスク表現は、データセットまたはタスクからグローバル平均により集約された特徴量ベクトルを用いる
- ハイパーパラメータはone hotベクトルにより表現される
- 回帰ベースの最適化にすることでランクベースの最適化と同等になるらしい
- タスクによって性能のばらつきがあるので性能の分散を使って正規化する
- 同じようなハイパーパラメータ構成になるデータセットは同じ表現をされるべきだ、という正則化が付与されている
- よりタスク表現を意味のあるものにするため
- 同じデータセット内から持ってきたバッチはそれら同士が同じ表現である必要があるので、その正則化を付与する
検証方法
- 10の画像分類データセット(BookCover30, Caltech256, DeepFashion, Food101, MIT Indoor Scece Recognition, IP102 Insects Pests, Oxford-IIIT Pets, Places365, SUN397, Descrubable Texture Dataset)を使用
- バックボーンアーキテクチャにはSE-ResNeXt-50とShuffleNet-v2-x1を使用
- 評価メトリクスにはHyperSTARが予測したランキングを反映させるためAP@10を使用する
- 真のハイパーパラメータと予測ハイパーパラメータ推奨リストを構築し比較することでAP@10を計算する
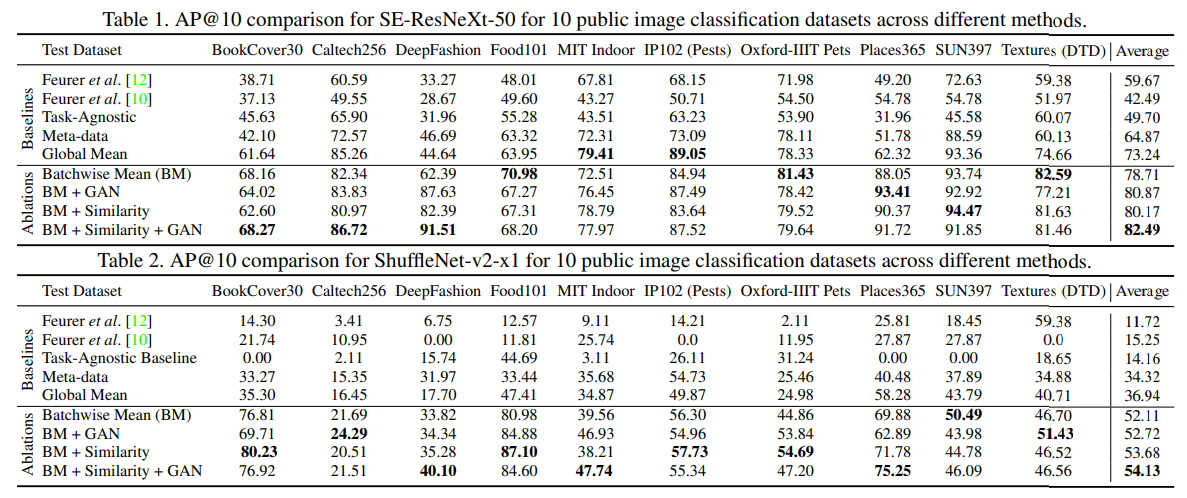
- バッチワイズ平均、類似性、敵対的正則化についてablation studyを実施した
- 期待通り、正則化を行うことでデータセット-ハイパーパラメータ構成の結合に対して意味のある特徴を学習することができることを示している
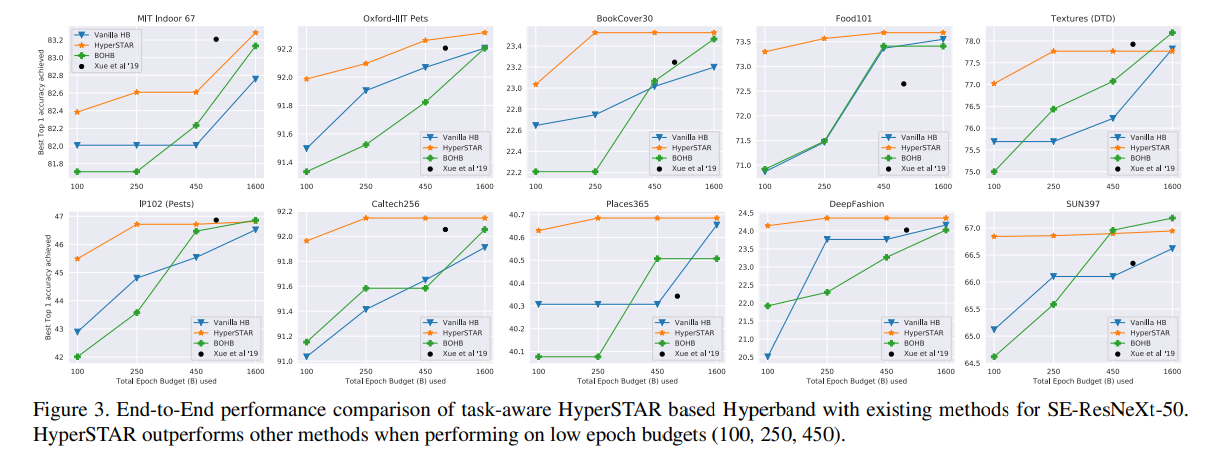
- 既存のメタラーニングに基づくウォームスタートハイパーパラメータ最適化手法との比較
- 低エポックバジェットで実行したときに特に他の手法より高い性能が出せている
議論
- モデルアーキテクチャ部分図くらいでしかちゃんと書かれてなくない
- 知りたい部分だっただけにどういう意図でそういうアーキテクチャになったのか書いておいてほしかった
- 目的関数周りはめちゃちゃんと書かれていて助かる
*****
Non sunt multiplicanda entia sine necessitate
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025