Decision Transformer: Reinforcement Learning via Sequence Modeling
reading papers
どんなものか
- オフライン強化学習の問題においてTransformerをうまく適用させた
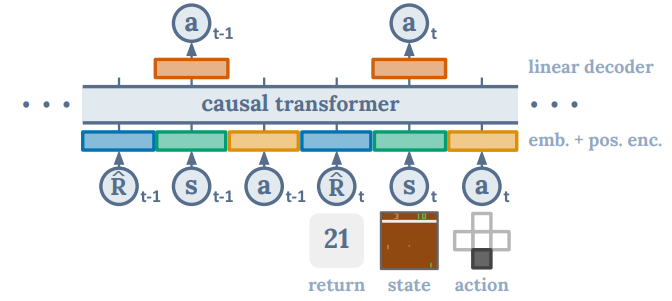
- GPTベースのアーキテクチャにより強化学習の問題設定における系列情報(状態、行動、収益…)を予測させることで、ある状態が入力の時に過去の系列情報も加味したうえで次の行動として適切なものを出力できるようにする
- 報酬ではなく収益
- 収益の最大化を目指すためモデルへの入力も収益にする
先行研究と比べて
- 強化学習、オフライン強化学習ではTD学習のように信用割り当て問題を解決するためなどでブートストラップを用いる
- 対してTrasnformerを使ったアプローチでは長期的な系列データをそのまま用いて直接的に信用割り当てを行うことができる
技術や手法のポイント
- GPTベースのTransformerアーキテクチャ
- 基本はGPTそのままであるが、自己回帰生成を可能にするためにattentionを計算するときに自分より前のトークンのみを使って計算をする
- 入力は報酬ではなく収益
- これにより条件付き生成が可能となり、例えば収益が高い行動はエキスパートによる行動(良い行動を予測)などができる
- また単純な模倣学習とは異なり質の悪いサンプルが混ざっていても関係なく学習できる
- 遷移情報の表現
- 状態、行動、収益それぞれについてembeddingを用意する
- embeddingは全結合層により行われ、状態は視覚的観測情報ならCNNによりembeddingする
検証方法
- Decision Transformer(DT), TD学習(強化学習ベースの手法), 模倣学習の3手法で精度の比較をおこなう
-
環境は行動が離散的(Atari)な環境と連続的(OpenAI GymのMuJoCoのロボットタスク)を使用
- Atari
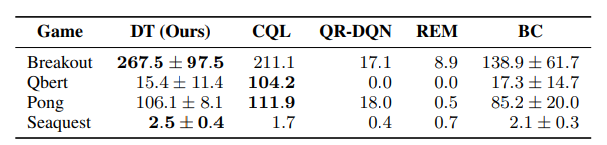
- ほとんどのタスクでCQLと同等もしくはそれ以上の精度を出せている
- OpenAI Gym
- D4RLベンチマークの連続制御タスクを使用
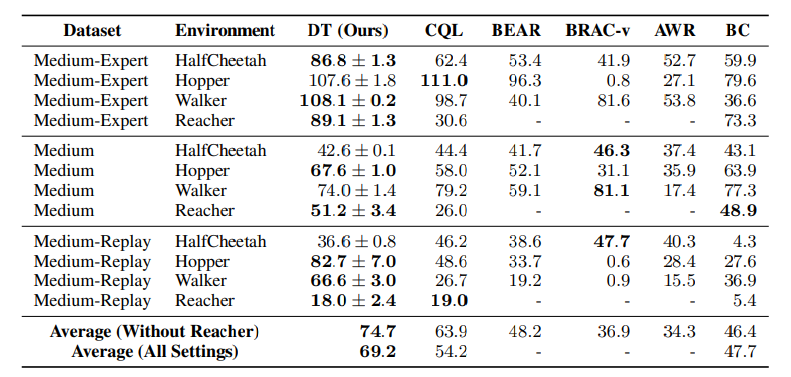
- データセット
- Medium:エキスパートポリシーの約3分の1のスコアを達成する中くらいのポリシーによって生成された1 millionタイムステップ分のデータセット
- Medium-Replay:Mediumポリシー(著者環境で約25k-400kタイムステップ学習)のパフォーマンスに訓練されたエージェントのリプレイバッファ
- Medium-Expert:Mediumポリシー1 millionタイムステップとExpertポリシー1 million タイムステップをまとめたデータセット
- ほぼすべてにおいて先行研究の手法を上回る結果を出せている
- その他検証
- 長期信用割り当てができるかどうか
- 3つのフェーズからなり長期的な信用割り当てが必要な環境を用いる
- 最初のフェーズでは鍵のある部屋におかれ、次のフェーズで空の部屋に置かれ、最後のフェーズでドアのある部屋に置かれる
- それぞれのフェーズで自由に行動でき、時間経過で次のフェーズにいく(おそらく)
- ドアは最初のフェーズで鍵を拾っていないとあかない

- この環境を用いてランダムポリシーで集めたデータセットで検証したところ、TD学習ベースでは学習が厳しかったがDecision Transformerは高い精度を出せた
- 3つのフェーズからなり長期的な信用割り当てが必要な環境を用いる
- 疎な報酬しか受け取れない環境でも機能するかどうか
- D4RLのベンチマークの遅延リターンの環境を用いて検証
- この環境はステップでの報酬を受け取れない代わりにエピソードの最後にまとめた累積報酬を受け取れるようにした環境

- 模倣学習は性質上何も変わらない
- TD学習は崩壊するがDecision Transoformerは頑健であった
- D4RLのベンチマークの遅延リターンの環境を用いて検証
議論
*****
Non sunt multiplicanda entia sine necessitate
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025