LIMA: Less Is More for Alignment
reading papers
-
どんなものか
- GPTを使用したfine tuningにおいて質の高い1000の対話データのみを用いることで、GPT-4のような大量の対話データを用いてinstract tuningされた対話モデルに匹敵する性能を出せた
-
先行研究と比べて
- GPTの対話のためのfine tuningとしてRLHFが良く用いられていた
- 対してこちらでは、質を担保しさせすれば大規模である必要もRLHFである必要もなく普通のfine tuningで良い性能が出せる
-
技術や手法のポイント
- 1000例のalignmentデータセットでLLaMa 65Bモデルをfine tuningする
- dataset
- コミュニティのQ&Aフォーラムと手動で作成された例を用いる
- コミュニティQ&AフォーラムにはStack Exchange、wikiHow、Reddit(ただしユーモアのある回答などもあるのでより手動的なキュレーションを行った)を使用した
- データのさらなる多様化のため著者らもプロンプト、回答の作成を行った

- 訓練データセットの例
- fine tuning
- パラメータ
- AdamW ($β_1 = 0.9 , β_2 = 0.95 $, weight_decay = 0.1)
- Learning rate : 1e-5から学習終了までに1e-6に線形減衰させる
- batch size : 32 ( 2048 より長いトークンは切り捨てられる )
- dropout : 最初の層は0.0で出力層に近づくにしたがって0.3まで線形に上げる
- epoch : 15
- パラメータ
-
検証方法
- Human Evaluation
- 各テストプロンプトに対して1つの回答を生成する
- クラウドワーカーにLIMAの出力を各ベースラインと比較しどれが好ましいかをラベリングするよう依頼
- 人間の代わりにGPT-4でも試した
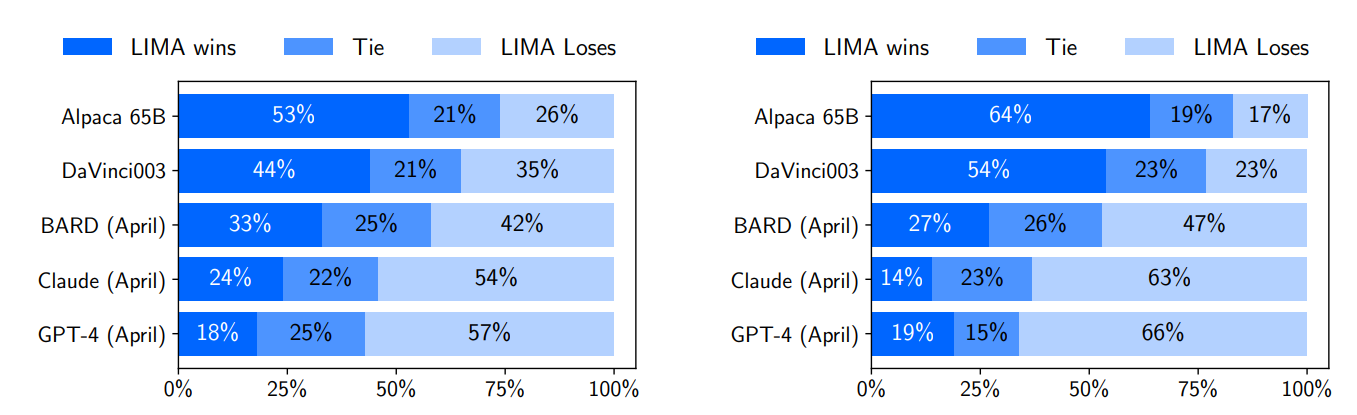
- 人間、GPT-4ともにLIMAの回答を好む傾向にあった
- ベースラインはAlpaca(LLaMa 65BをAlpacaデータセットでfine tuningさせる)、DaVinchi003(いわゆるChatGPT-3.5)、BARD(PaLM)、Claude(RLHFでfine tuningされた52Bのモデル)、GPT-4
- 同じベースラインのAlpacaに対して少ないfine tuningのデータセットで勝てている
- Human Evaluation
-
議論
- 少ないデータセットでできるとは言ってもその分質は必要になってくるので結局ある程度データセットにコストが変わることには変わりない
- 使用用途が明確な時にそれ用にデータセットを作ってAlignmentできる(しやすそう)というのは結構嬉しいか
*****
Non sunt multiplicanda entia sine necessitate
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025