Dropout Reduces Underfitting
reading papers
-
どんなものか
- 訓練初期のドロップアウトの適用が、モデルのunderfittingに対して効果があることを実証した
- ミニバッチ間の勾配の方向性のばらつきを学習初期段階において減らし、データセット全体の勾配と一致させる効果があることを実証
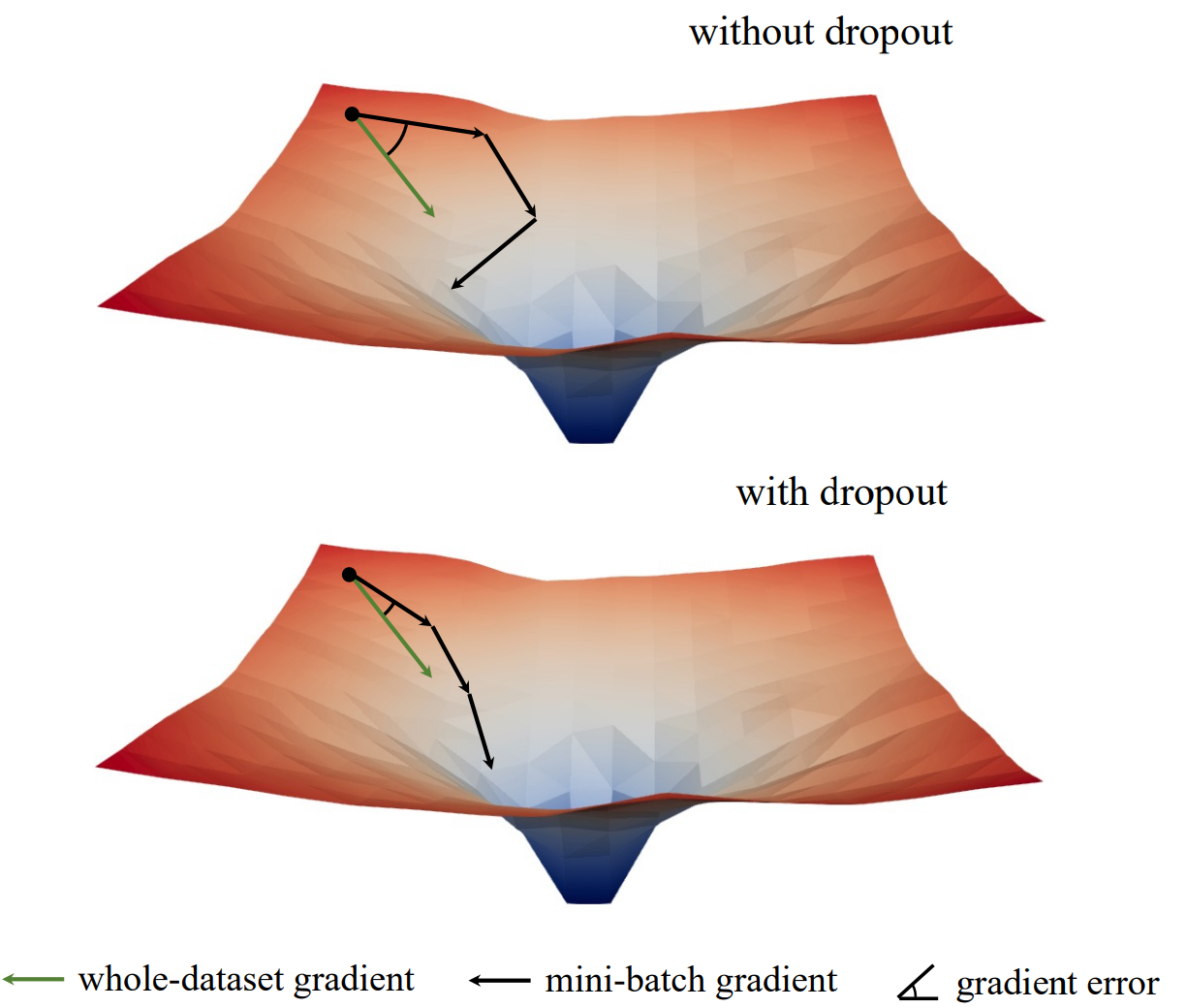
- 初期のdropoutではミニバッチの勾配がデータセット全体の勾配の向きと近づく
-
先行研究と比べて
- Dropout
- dropoutはモデルのoverfittingに対して効果があることが分かっていた
- またDropoutのスケジューリングなどDropoutのかけ方に対する研究などは数多くある
- しかしdropoutに関するほとんどの研究はoverfittingに対するものであり、本研究ではdropoutのunderfittingに対する効果の検証を行う
-
技術や手法のポイント
- Gradient normとModel distance
-
Gradient normを勾配gのL2ノルムで算出 ( $ \mathbf{g} _2$ ) -
Model distanceを二つのモデルのパラメータWのL2ノルムで計算 ( $ \mathbf{W}_1 - \mathbf{W}_2 _2$ ) - ViT-T/16のimagenetクラス分類の学習において、ドロップアウトを行わないベースラインと学習中ドロップアウト率を0.1とした2つのモデルの学習過程を比較する
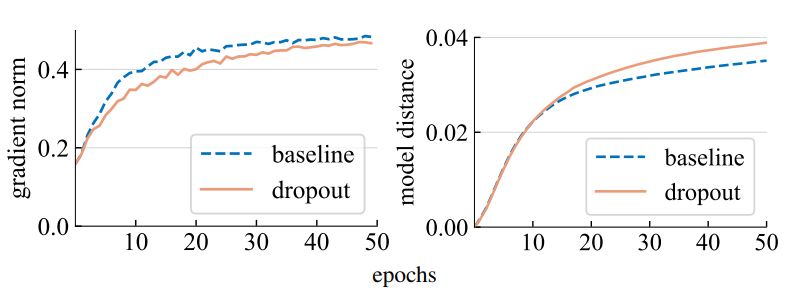
- 左はGradient norm、右は初期モデルとn epoch学習目のモデルのModel distance
- ドロップアウトモデルは勾配の大きさは小さいが、パラメータ空間での移動距離は大きい
- 歩幅は小さいが移動距離は大きいことから一定方向に進み続けていることが示唆される
-
- Gradient direction error
- データセット全体の勾配を正しい方向としたときに、ミニバッチの勾配がどれくらいその方向から離れているかを以下のように評価する - \(GDE = \frac{1}{|G|} \sum_{g_{step} \in G} \frac{1}{2} \left( 1- \frac{<g_{step}, \hat{g}>}{||g_{step}||_2 \cdot ||\hat{g}||_2} \right)\) - ただしg_stepはミニバッチによる勾配、g_hatは推論モードに設定したモデルの全バッチの勾配
- ViT-T/16のimagenetクラス分類の学習において、ドロップアウトを行わないベースラインと学習中ドロップアウト率を0.1とした2つのモデルの学習過程を比較する

- 勾配方向の誤差(GDE)は訓練の初期段階においてドロップアウトありのモデルの方が全体の勾配と一致する
- 正しい方向に進んでいることが示唆される
-
検証方法
- Imagenetクラス分類のタスクで評価を行う
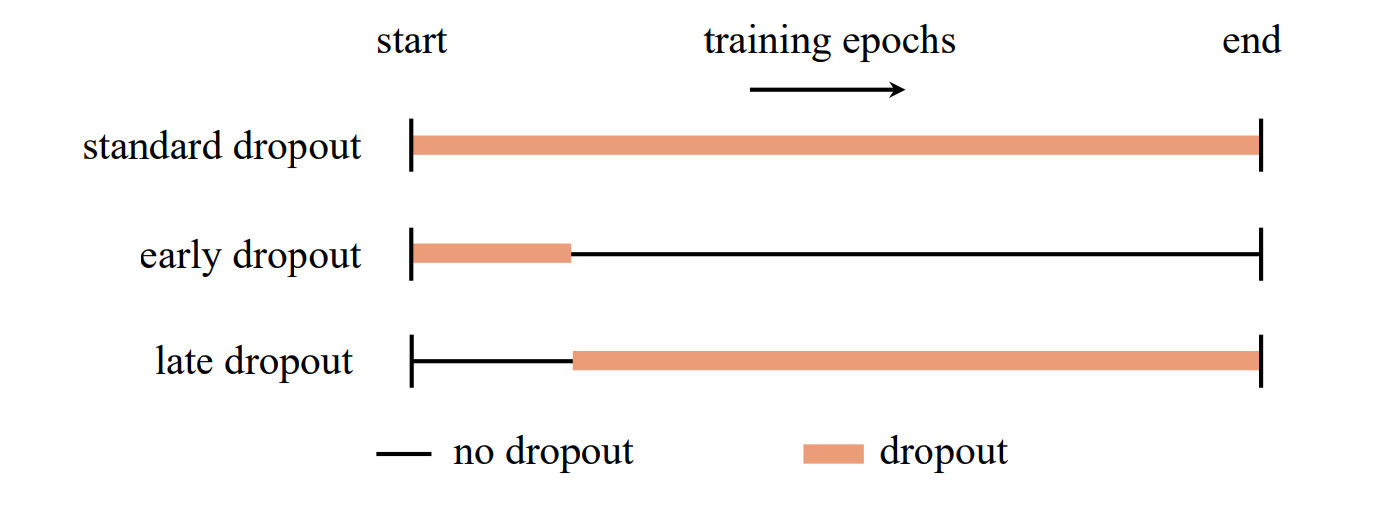
- Early Dropout
- ViT-T/16、Mixer-S/32、ConvNeXt-Femto、SwinF (ConvNeXt-Fと同等のサイズ)
- 全てunderfitting領域のモデルサイズ
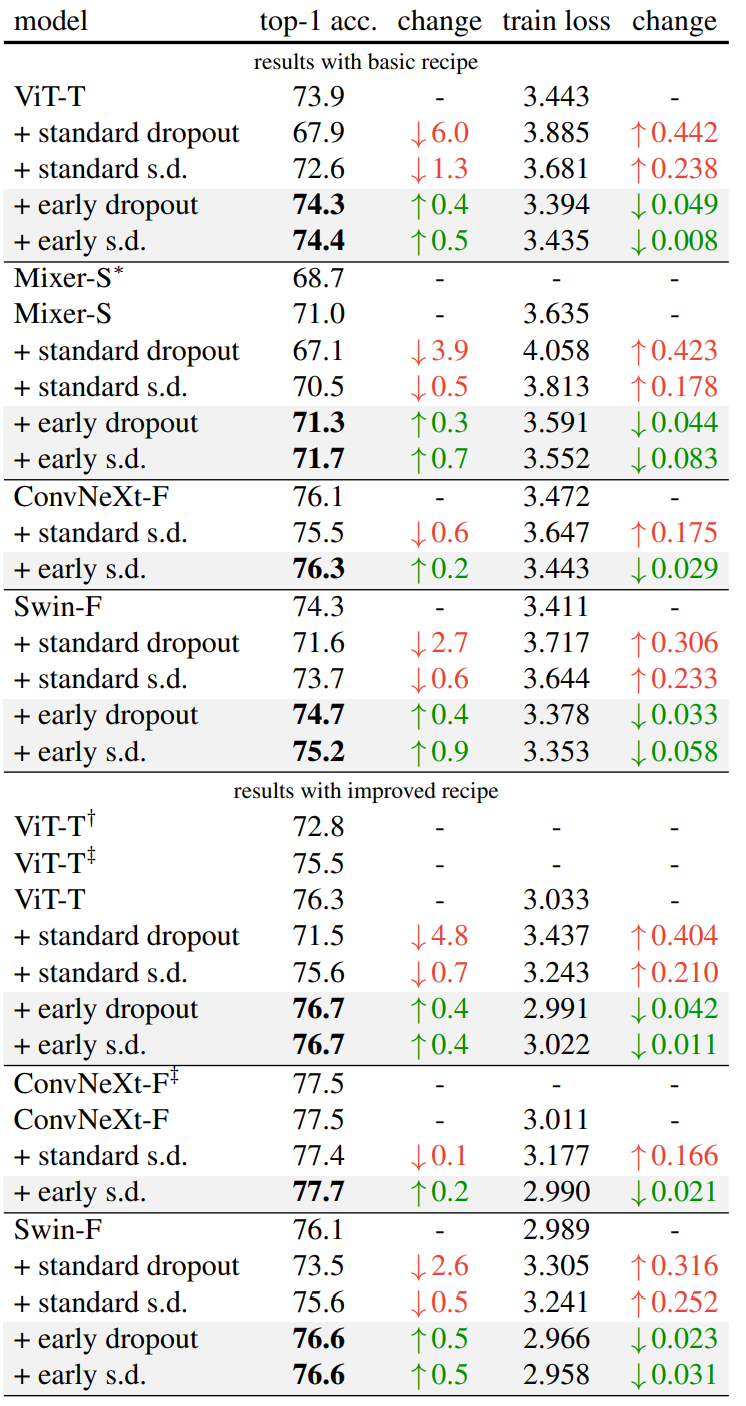
- s.d. はstochastic depth
- いくつかのパラメータ設定で行っているが、いずれもearly dropoutは性能を向上させている
- Dropout Epochs
- 合計600epochの訓練のうち、ドロップアウトをn epoch目まで適用させる
- デフォルトでは50epoch
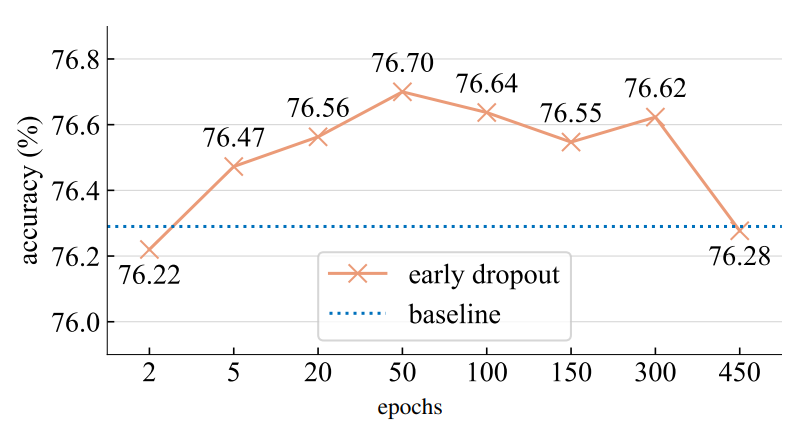
- 幅広いエポックで性能の向上が見られる
- 実用的な場面で採用しやすい
- 合計600epochの訓練のうち、ドロップアウトをn epoch目まで適用させる
-
議論
- top-1 accが0.数パーセント上がるのがどれくらいうれしいか
- 学習初期に正しい方向に進めるのが最終的な性能の寄与に影響を与えられるの、直感的ではない気がする
- 最終的に行き着くところは同じにならないのか
- 学習率のスケジューリングなどでは初期の学習に対する近い影響を与えられないだろうか
- 実装がかなりシンプルに達成できそうなのは実用上うれしそう
*****
Non sunt multiplicanda entia sine necessitate
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025