Language Models are General-Purpose Interfaces
reading papers
-
どんなものか
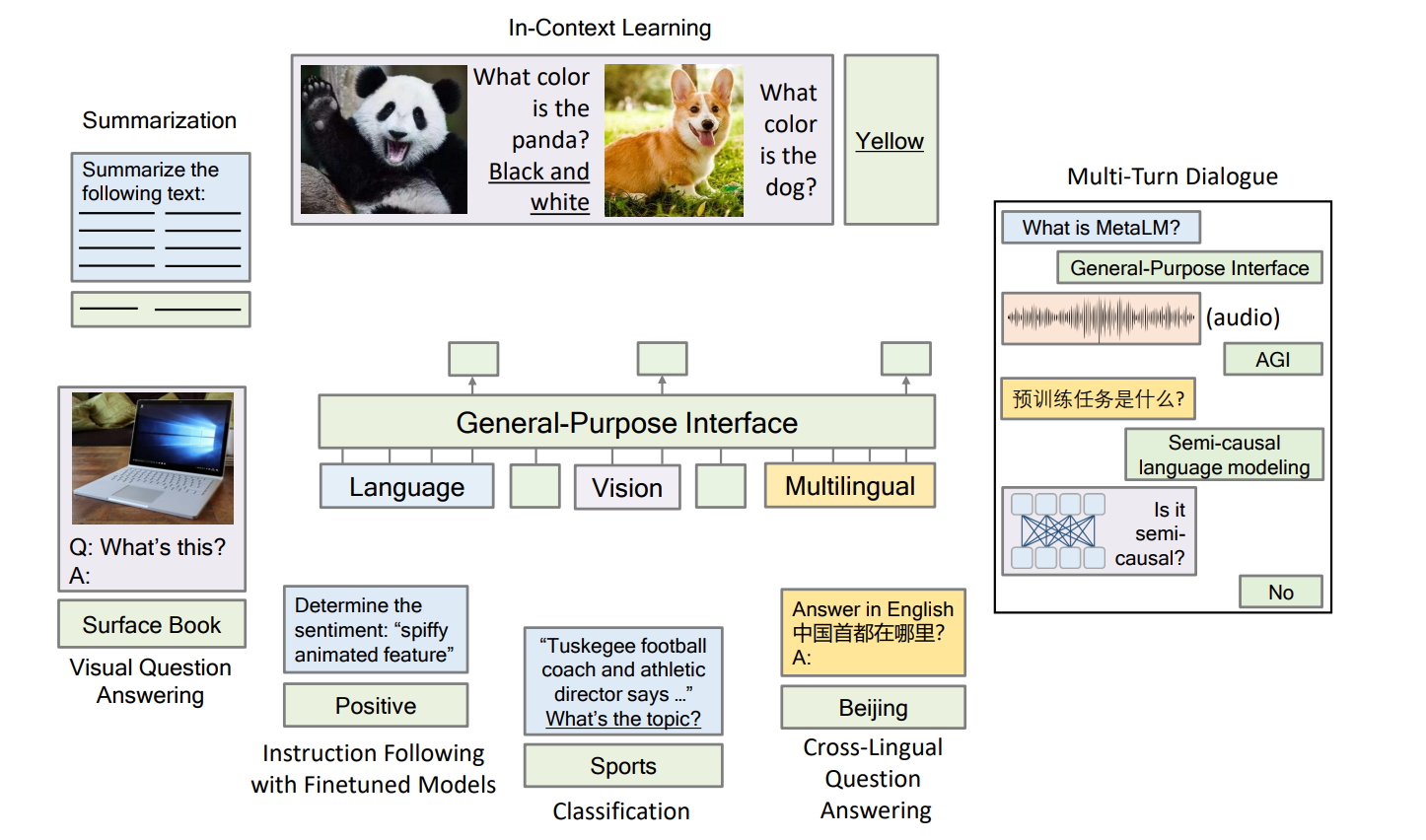
- Language Model (GPT)は言語タスクだけでなく視覚やマルチモーダルなタスクにも対応する汎用的なインターフェースとして機能することを示した
- マルチモダリティにも関わらずZero-shot性能やin-context learningなどを可能にし、言語ベンチマークや視覚言語ベンチマークの実験結果からタスク専門のモデルを凌駕しうる結果が得られた
-
先行研究と比べて
- 大規模言語モデル(GPT)は言語タスクの基盤モデルである
- しかし言語タスクに限らず視覚やマルチモーダルなタスクにも対応する汎用的なインターフェースとして機能する
- 言語モデルは広い出力空間を持つので対応力も広い
-
技術や手法のポイント
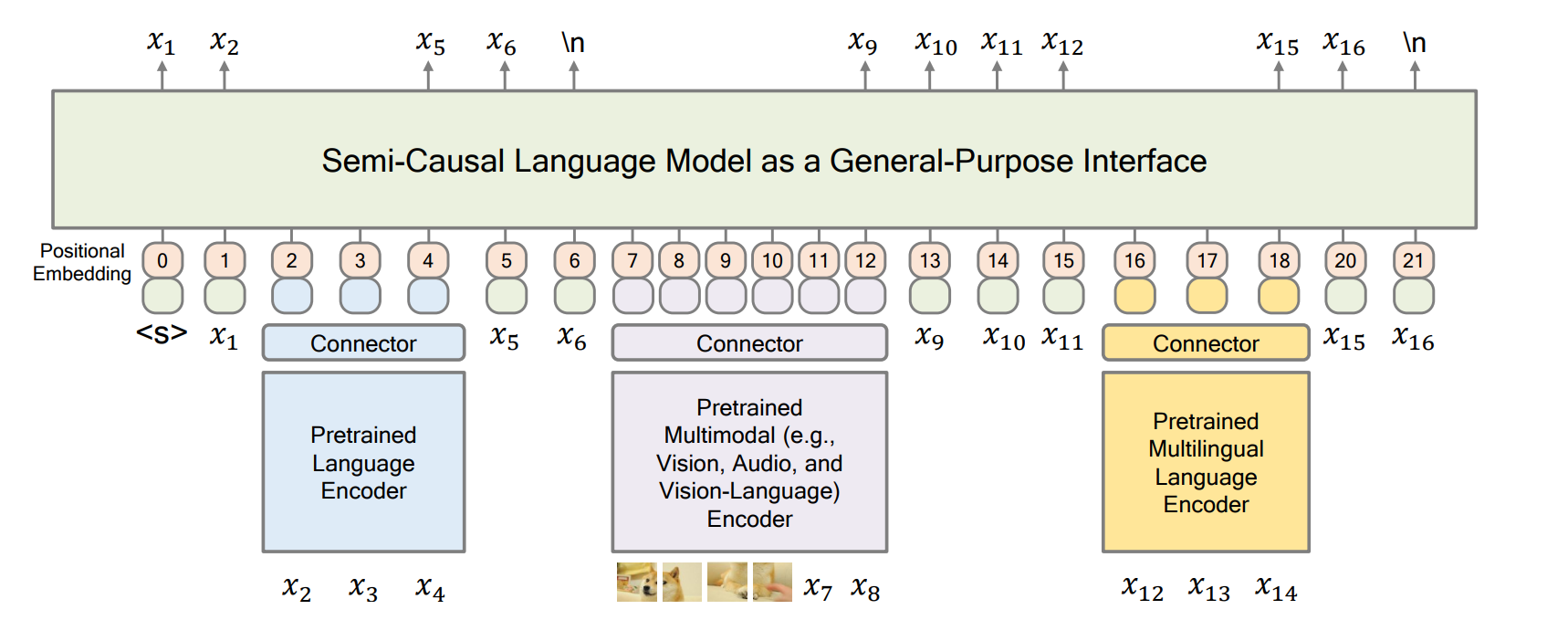
- 事前訓練されたエンコーダーの集合(モデル自体はTransformer encoder)をTransformer decoderに全て入れて処理をすることができる
- vision-languageエンコーダーもgptの学習と同じような次単語予測で学習する
-
検証方法
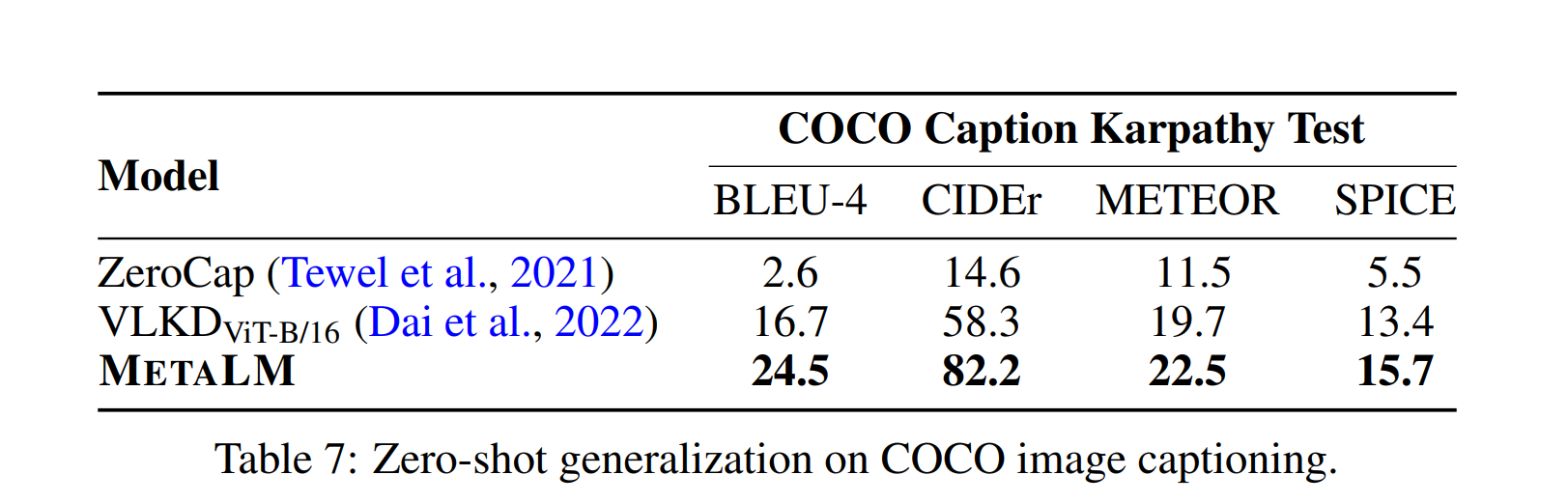
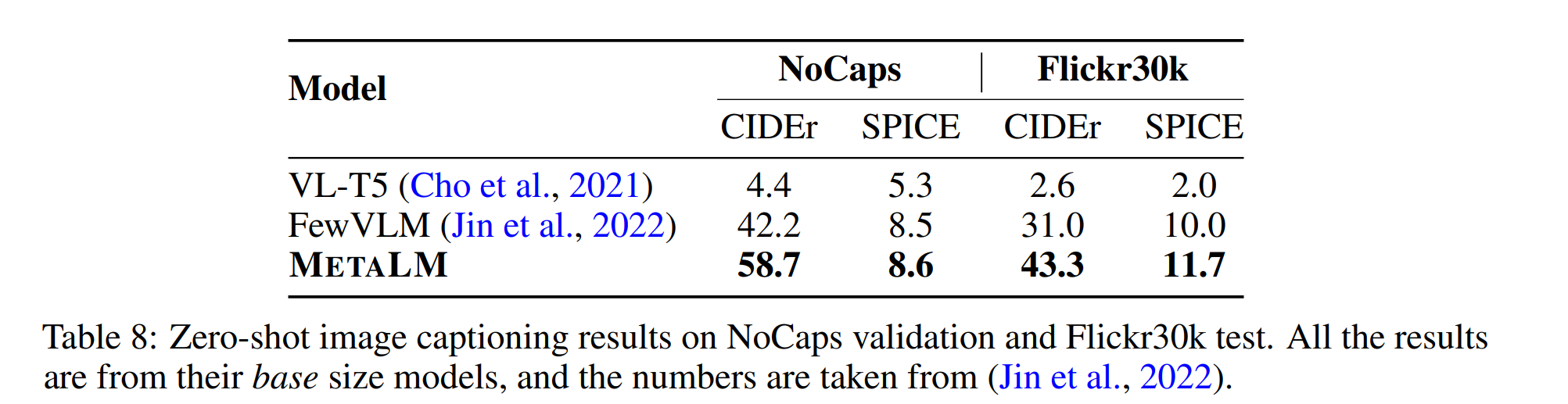
言語タスクは割愛- Image Captioning
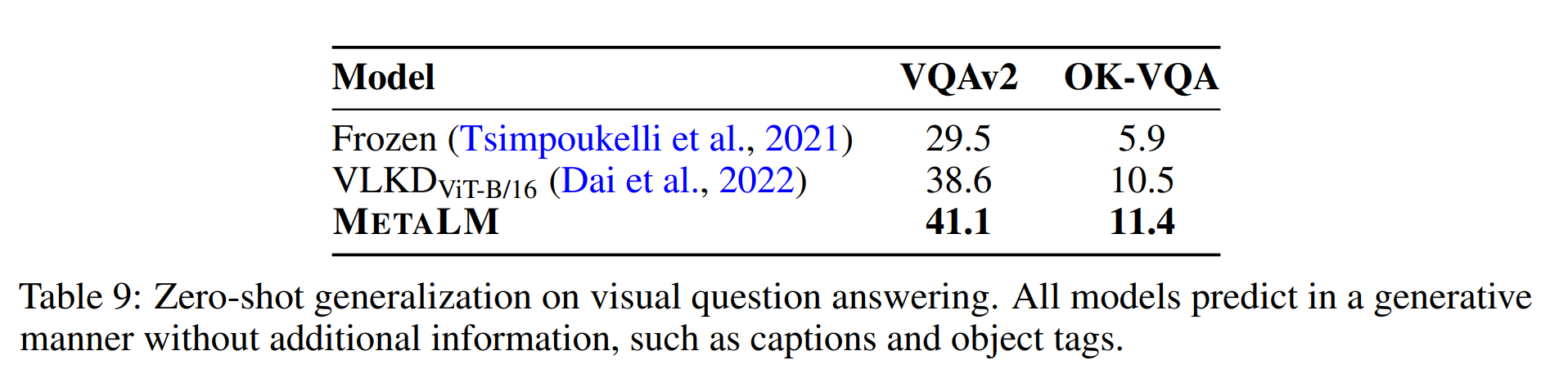
- Visual Question Answering
 -
-
-
議論
- microsoft
- kosmosのモデルアーキテクチャのもと
*****
Non sunt multiplicanda entia sine necessitate
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025