Retrieval-Augmented Multimodal Language Modeling
reading papers
-
どんなものか
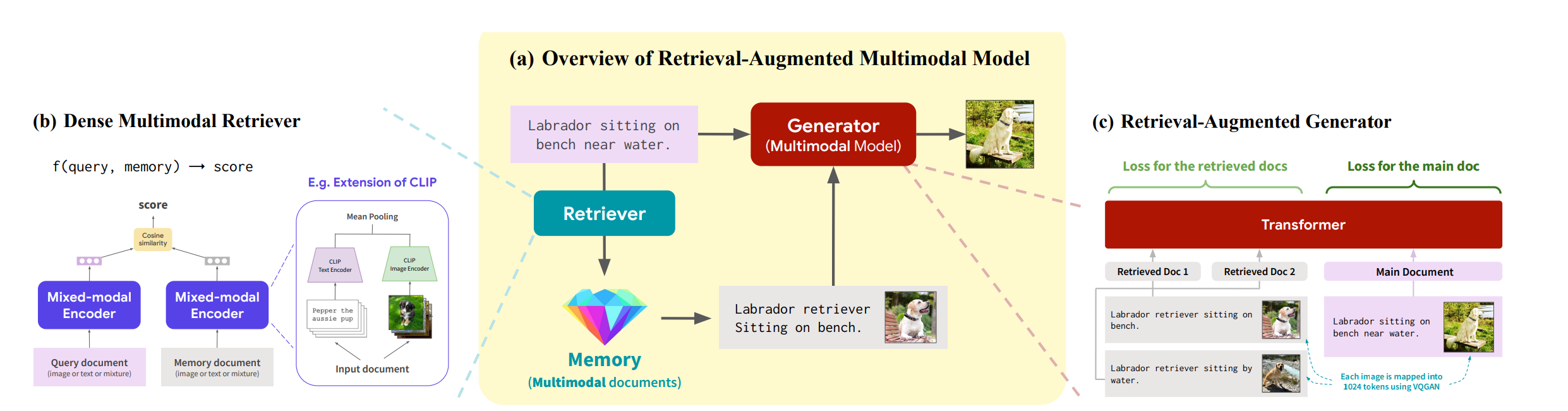
- Retrieverによって外部メモリ(例えばウェブ上の文書)を参照できるようにしたマルチモーダルモデルを提案した
- 大規模モデルでは全てをモデルパラメータに格納するため多くの知識のためによりデカいモデル、データセットが必要になってしまうため軽くしたいモチベーションがある
-
先行研究と比べて
- 自然言語処理において検索補強型モデルが近年有望視されていた
- 本論文では検索補強型モデルの枠組みをマルチモーダルモデルに拡張させた
-
技術や手法のポイント
- 検索拡張言語モデル
- 検索モジュールRと生成モジュールG(e.g. LM)
- Rは入力系列xと外部記憶文書Mを入力として文書のリストS( $\in M$ )を返す
- GはxとSを入力としてターゲットyを返す
- yは典型的な言語モデル(xの続きを予測する)に従う形の推論を行う
- モデルアーキテクチャ
- CM3(Causal masked multimodal model)
- モデルの入力は画像とテキスト
- 特に本論文ではHTML形式に従わせる
- 例えば
<img alt=[text] src=[image]> - textはテキストトークン、imageはVQGANによって1024tokenにトークン化
- 例えば
- CM3(Causal masked multimodal model)
- 訓練
- image-textペアを用いた次単語予測により学習を行う
- 例えば x_input = “Photo of a cat: [image]” のように元のシークエンスを次単語予測で学習させるか、または x_input = “Photo of a
: [image] a cat" のようにマスクをかけて最後にそのマスクを持ってきてマスクを予測する
- 検索器
- CLIPで特徴量化しメモリ内でcos類似度で近いものを取ってくる
- その後生成モジュールへの入力は主入力列xの前に追加する
- 検索された文書はcontextとなる
- また学習時には検索文書部分の損失も活用する
-
検証方法
- 学習データはLAIONデータセットを使用する
- Stable Diffusionの前処理に従い150M(1.5億)のテキスト画像ペアを使う
- 外部メモリにも同じセットを使用する
- 生成モジュールには2.7BパラメータのTransformer Decoderを使用する
- 比較として同サイズで検索モジュールを使わないただのTransformerも学習させる
- 画像生成
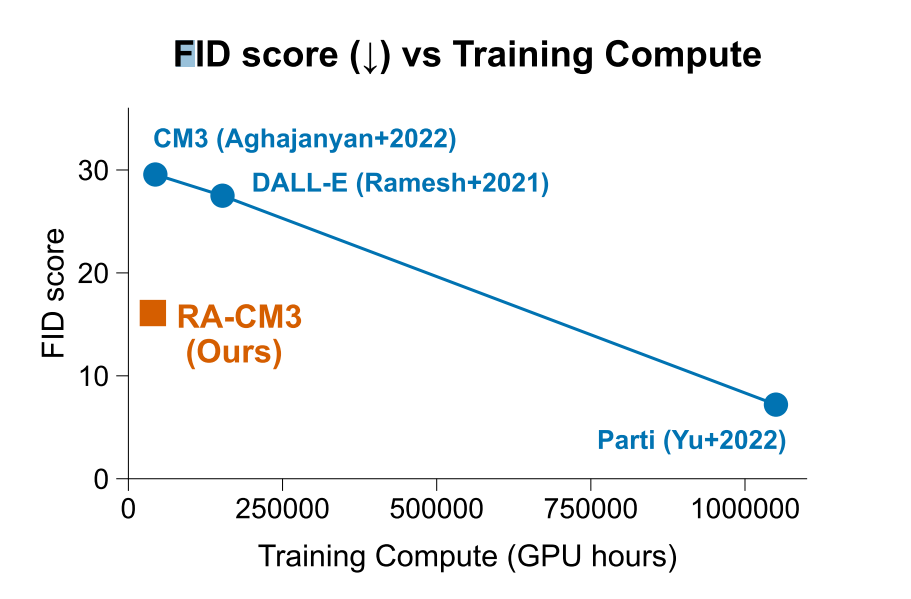
- 同じパラメータ数のものよりは性能が良く、訓練効率も良い結果となった
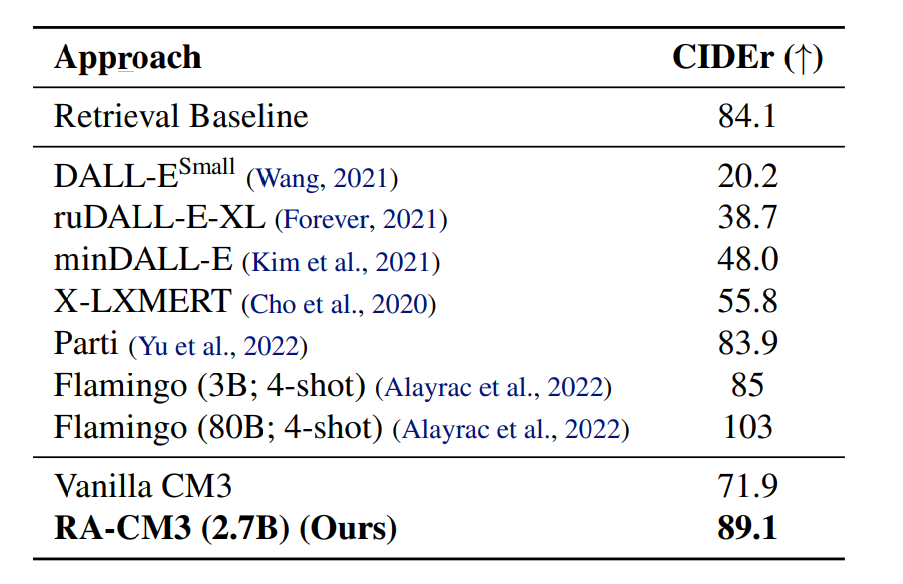
- キャプショニング
- MS-COCOデータセットで評価
- 稀な知識の合成
- 検索能力を有しているため、世界知識や知識の合成を必要とするタスクを得意とする

- フランス国旗+月、ラシュモア山+日本の桜
- などのキャプションからの画像生成の精度の向上が見て取れる
-
議論
- 学習時間は256台のA100で5日
- GPUあたり16のシーケンスのバッチサイズ
- 検索補強によりモデルは全ての文書をモデルのパラメータに当てはめ覚える必要がなくなり学習効率が向上したのではないかと論文内で示唆されている
- 画像生成よりのマルチモーダルモデル
- キャプショニング以外のタスクの性能などが検索補強で上げられるか気になる
- 例えばdetection, VQAなど
- 画像生成は知識を検索しながら生成するのが上手く働いているけど他のタスクだとここまで上手くいかないんじゃないか、どうだろう
*****
Non sunt multiplicanda entia sine necessitate
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025