multitask prompted training enables zero-shot task generalization
reading papers
-
どんなものか
- 近年の大規模言語モデル(LLM)が多様なタスクにおいてゼロショット汎化性能が高いことが示されている。
- このゼロショット汎化性能が暗黙的なマルチタスク学習の結果によってもたらされていることを示した。
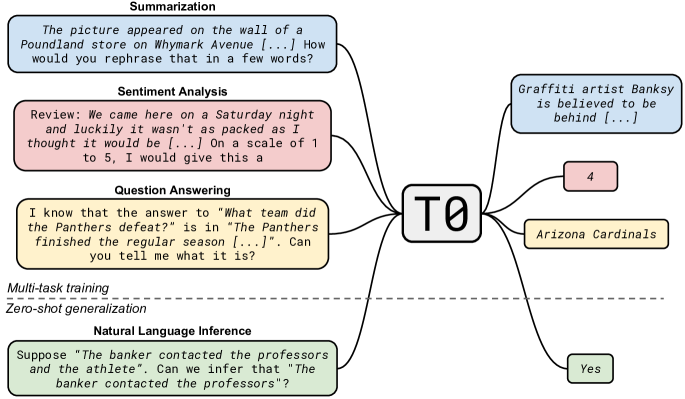
-
先行研究と比べて
- FLANは本論文と同じようなマルチタスク・プロンプト訓練によってゼロショット汎化を可能にする
- FLANと比較するとT0のゼロショット性能はCBとRTEで優れており、特筆すべきはFLANではモデルサイズが10倍以上でかいにもかかわらず近いゼロショット性能が出せている(FLAN: 137B, T0: 11B)
-
技術や手法のポイント
- マルチタスク混合で教師あり学習をすることでゼロショット汎化性能が高くなる
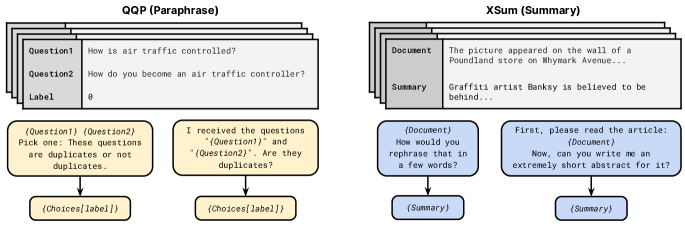
- マルチタスクを統一的に扱うためそれぞれのタスクにテンプレートを作成
-
検証方法
- 使用モデル
- T5のようなエンコーダデコーダ型のTransformerモデル
- マスク言語モデリング+LMの事前学習
- 訓練
- すべての訓練データセットから全ての例を組み合わせてシャッフルすることでマルチタスク訓練を組み立てる
- 各データセットからデータセット内の例数に比例してサンプリングすることと同じ
- 訓練データセットが2桁異なるものも存在する
- サンプリングの目的のために500000/num_templatesの例を持つものとして扱う
- シーケンス長は1024と256に切り捨てて、パッキングを用いて複数の訓練例を1つのシーケンスにまとめる
- すべての訓練データセットから全ての例を組み合わせてシャッフルすることでマルチタスク訓練を組み立てる
- 検証
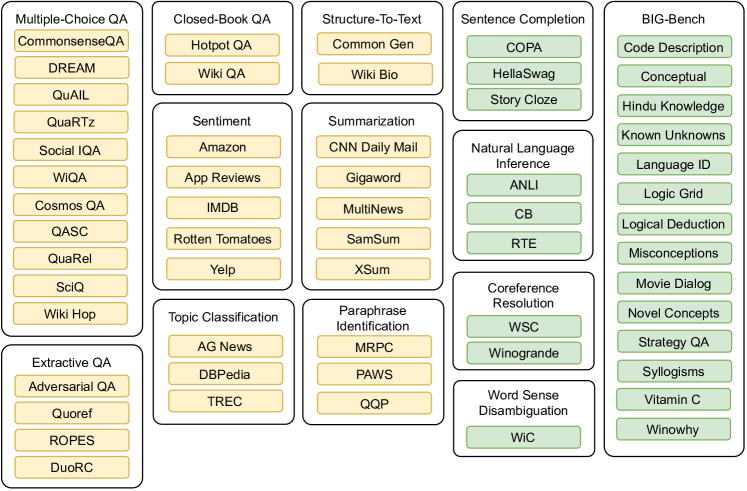
- 黄色のデータセットのサブセットは訓練検証のデータセットタスクであり、緑はテストデータのデータセットタスク
- 結果
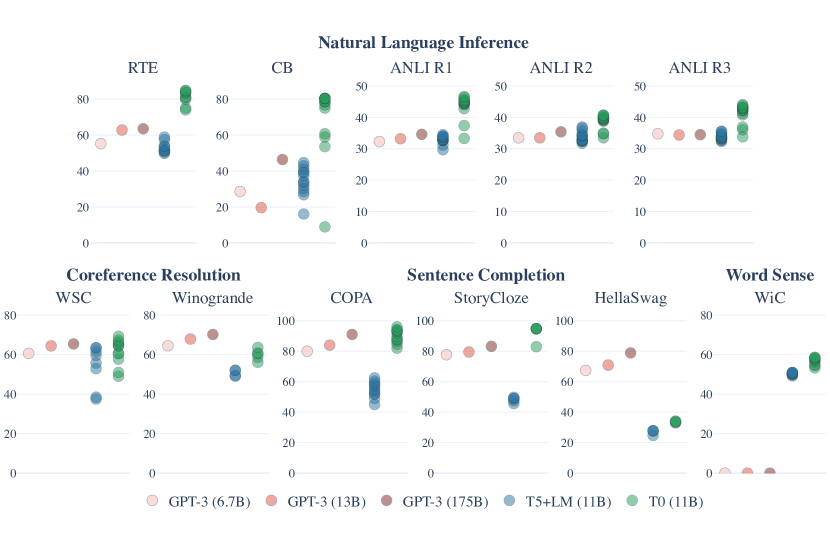
- T0が提案手法(T5+LMモデルを複数タスクでファインチューニングしたモデル)
- データセット数とテンプレートプロンプト数に対する頑健性
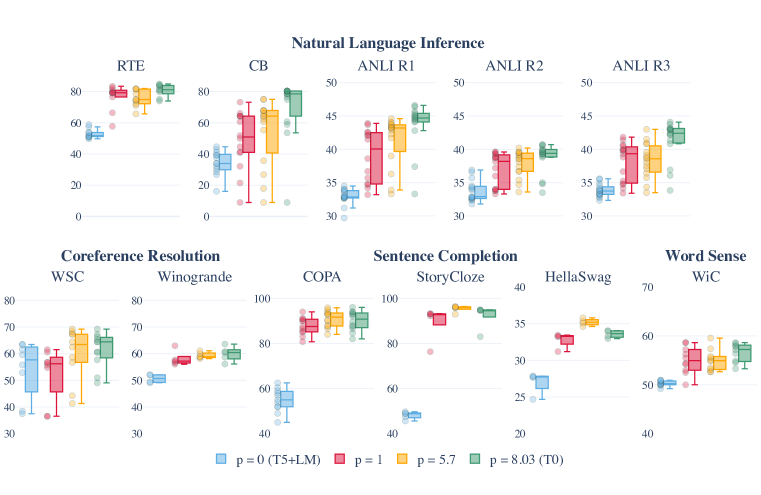
- データセットあたりの平均プロンプト数pを減らすと性能が下がった
-
議論
直感的にはまぁそれはそうというような感じではある
*****
Non sunt multiplicanda entia sine necessitate
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025