Symbol tuning improves in-context learning in language models
reading papers
-
どんなものか
- 自然言語ラベルを任意の記号(例えば「foo/bar」)に置き換えてファインチューニングを行った
- symbol tuningはモデルがタスクを理解するために指示や自然言語ラベルを使用できないので入力とラベルのマッピング(in-context learning)を半強制させる
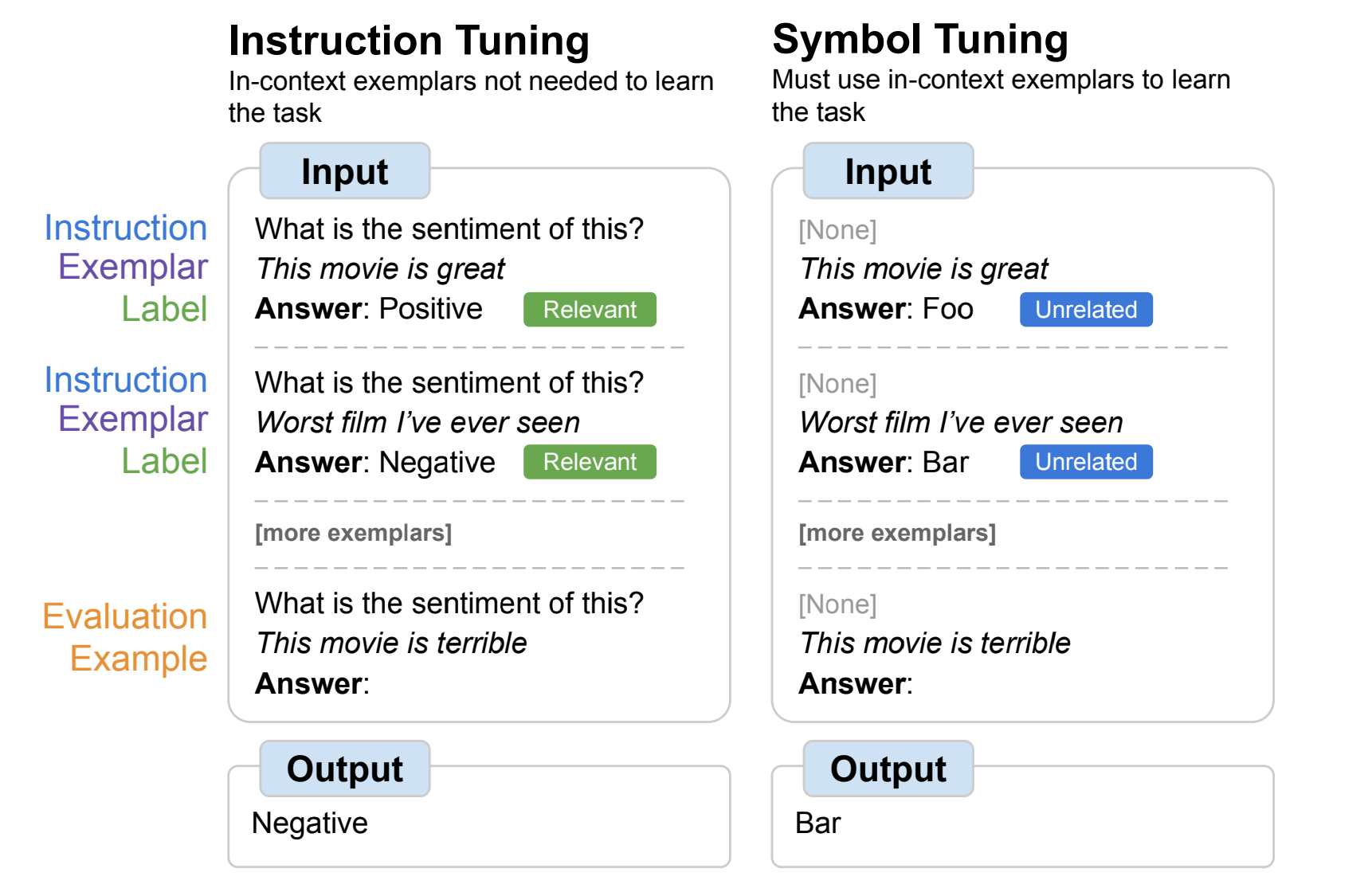
-
先行研究と比べて
- transformerのIn-Context Learning能力についての研究は多分にある
- 自然言語環境において言語モデルは無関係なプロンプトや誤解を招くようなプロンプトが与えられた場合でもfine tuning中に同じ速度で学習できることを示した
- より広いレベルではラベル空間にノイズを加えたりシャッフルしたり正則化したりすることでシステムの学習と新しいタスクへの適応がよりうまくいくことを発見した
- 本論文はラベル増強の一形態とみなすことができる
- しかし大規模な言語モデルのチューニングに適用するという点で決定的に異なる
-
技術や手法のポイント
- 一般には意味のない記号をIn-context learningに使うことで、few shotの例を見ることを強制させる
- fine tuiningに使う学習データはHuggingFaceの一般に公開されているNLPタスクを用いる
- symbol tuningは離散的なラベルが必要なため分類タイプのタスクのみを用いる
-
検証方法
- 実験ではPaLMをInstruction tuningしたFlan-PaLMを使用する
- モデルサイズは8B, 62B, 540Bのものを使用
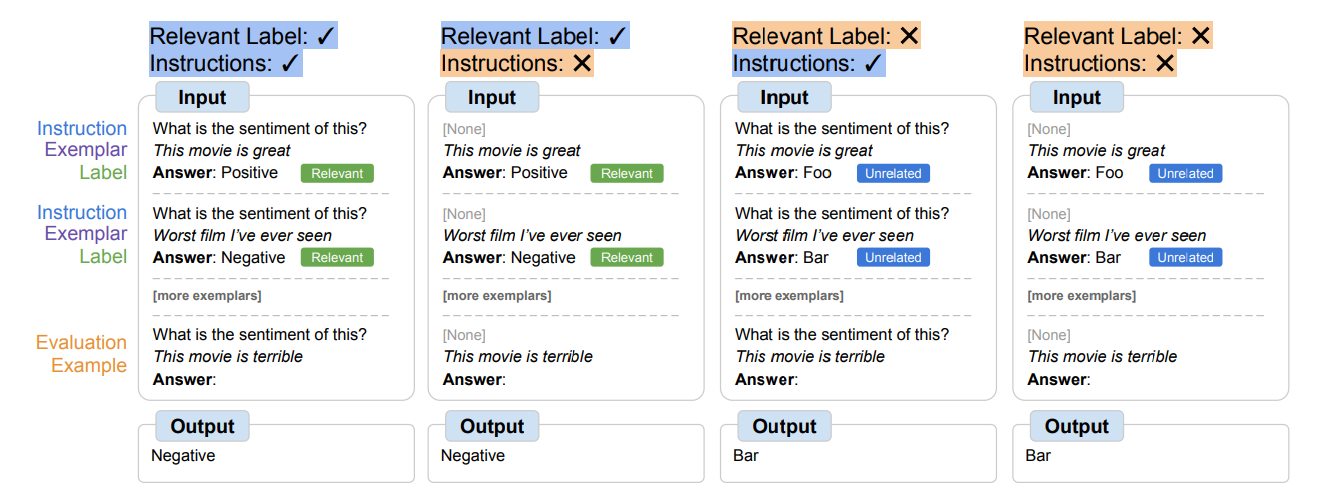
- 検証では自然言語ラベルとInstructionを与えるかどうかを変化させる
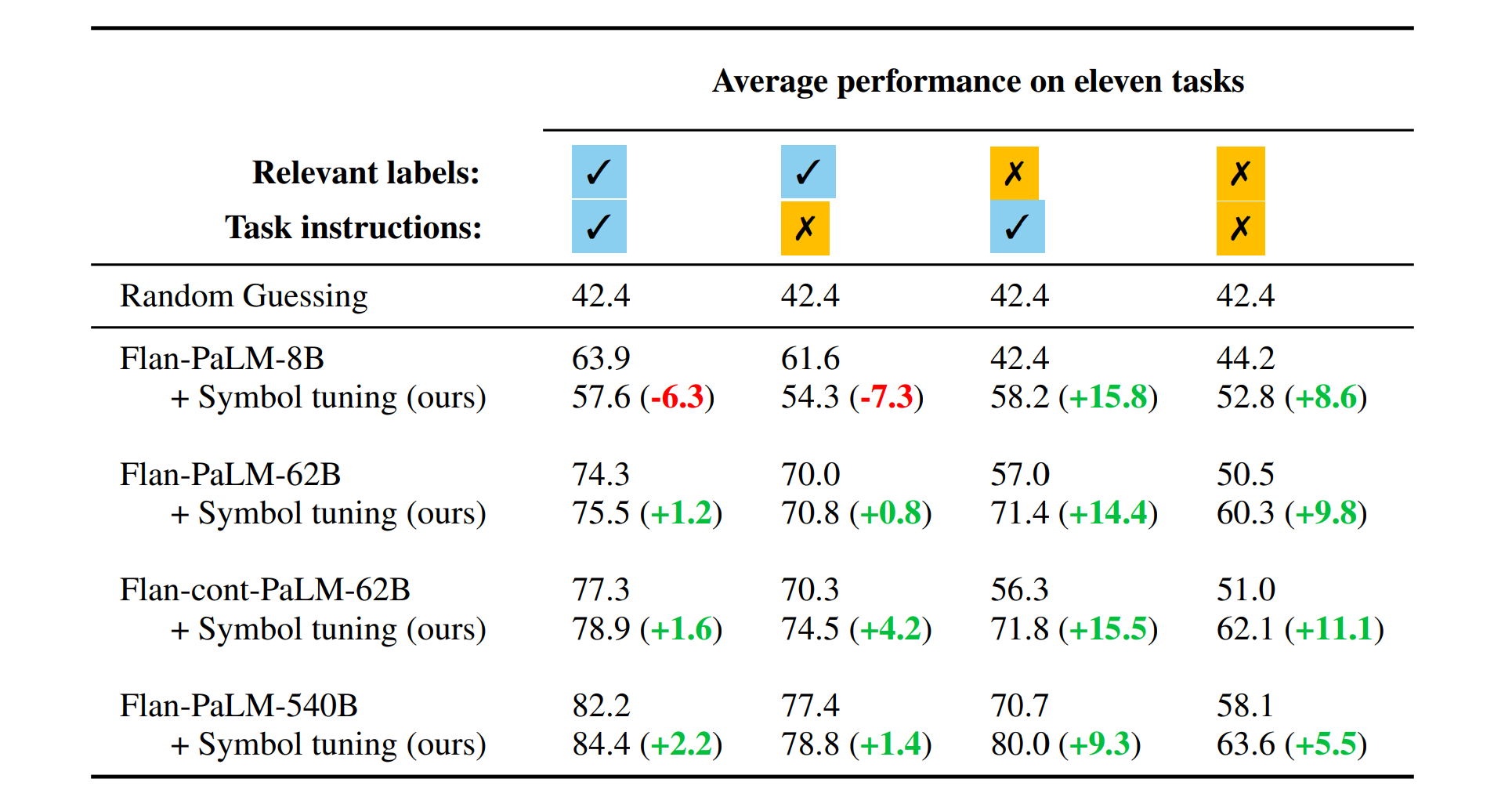
- 結果としてsymbol tuningは62B以上のモデルにおいて全てのIn-Context Learningの設定において性能が上がった
- symbol tuningによりfew shotでのラベルの対応付けを学習する際により小さなモデルでも大きなモデルと同等の性能が得られることを示唆している
- 小さなモデルでラベルが利用できるときの性能が下がっているがこれはfine tuningにより事前知識が上書きされる可能性があることを示唆しているのかもしれない
- アルゴリズム能力の向上
- BIG-Benchのアルゴリズム推論タスクで評価
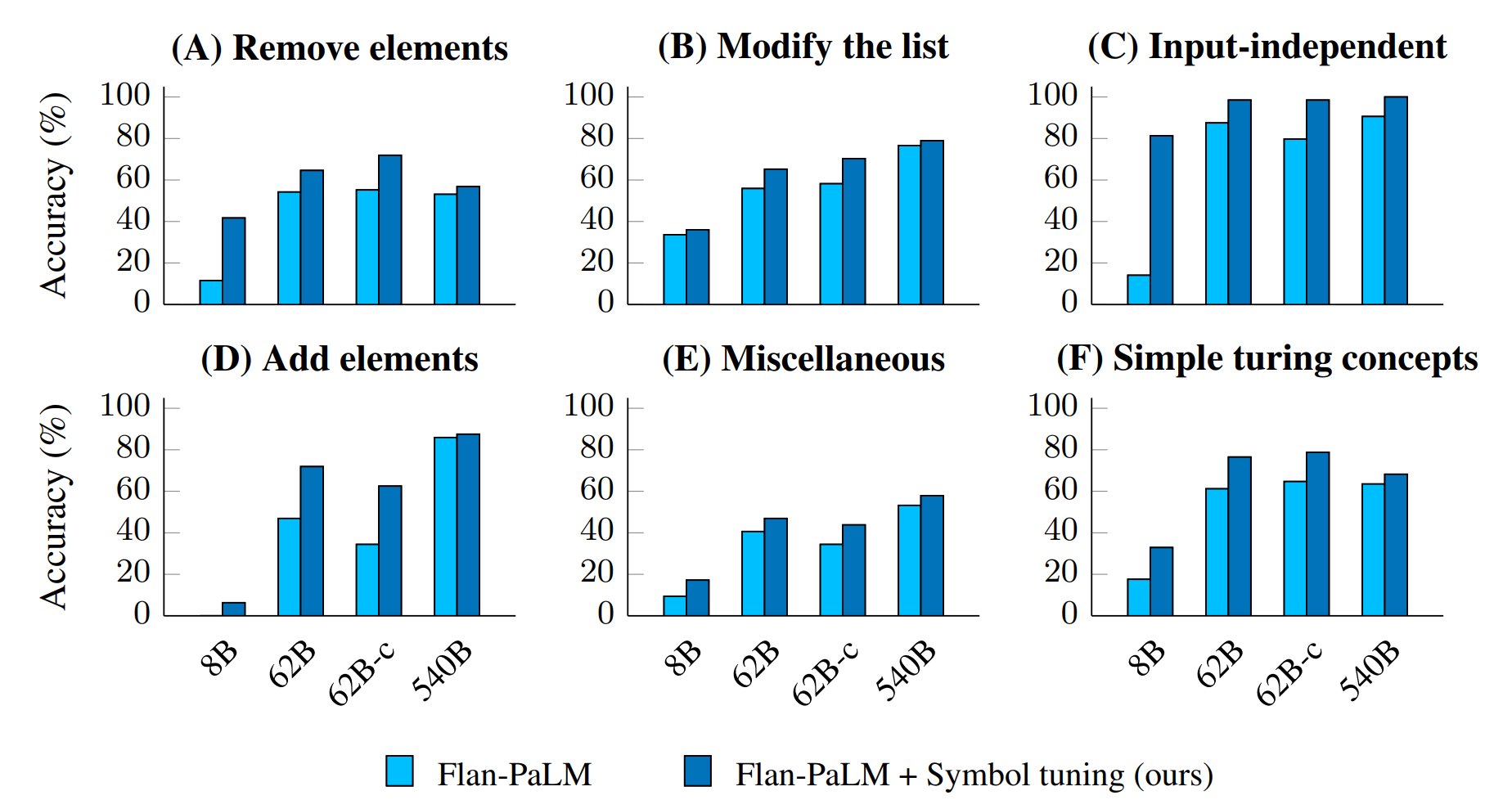
- Ablation Studies
- チューニングステップ数
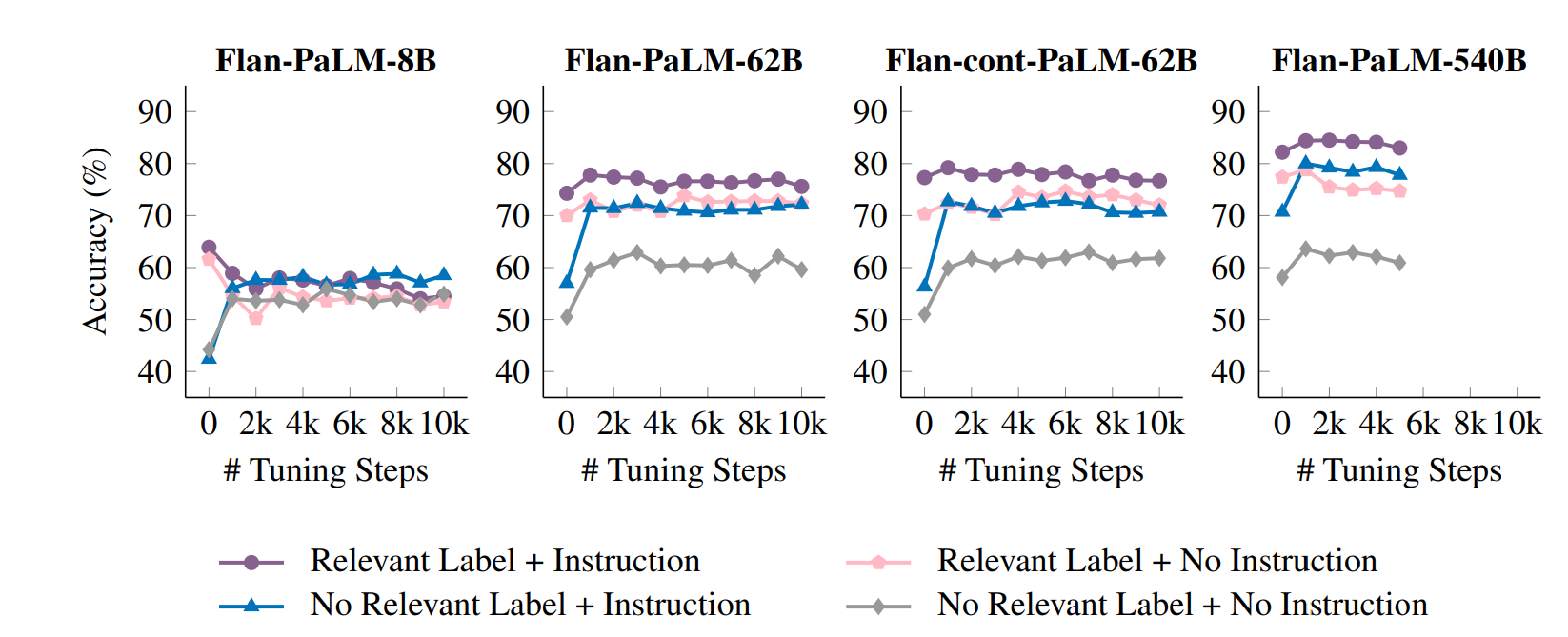
- 多くのモデルサイズで1k~2k程度のステップ数で十分な性能を獲得できることがわかる
- fine tuningデータの混合
- 小さなモデルではsymbol tuningデータに過剰に適合する可能性がある
- そこでInstruction tuningデータを混ぜてfine tuningを行うことを考える
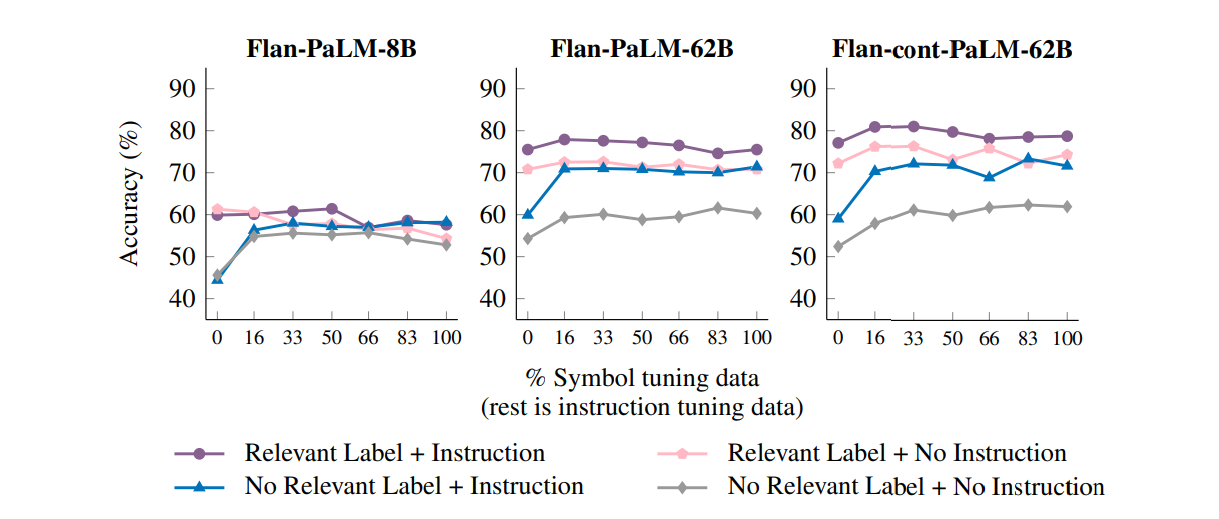
- symbol tuningデータは少なくても十分な性能が出せることが分かった
- データサイズ
- 学習の元となるデータセットの個数を変化させることで評価
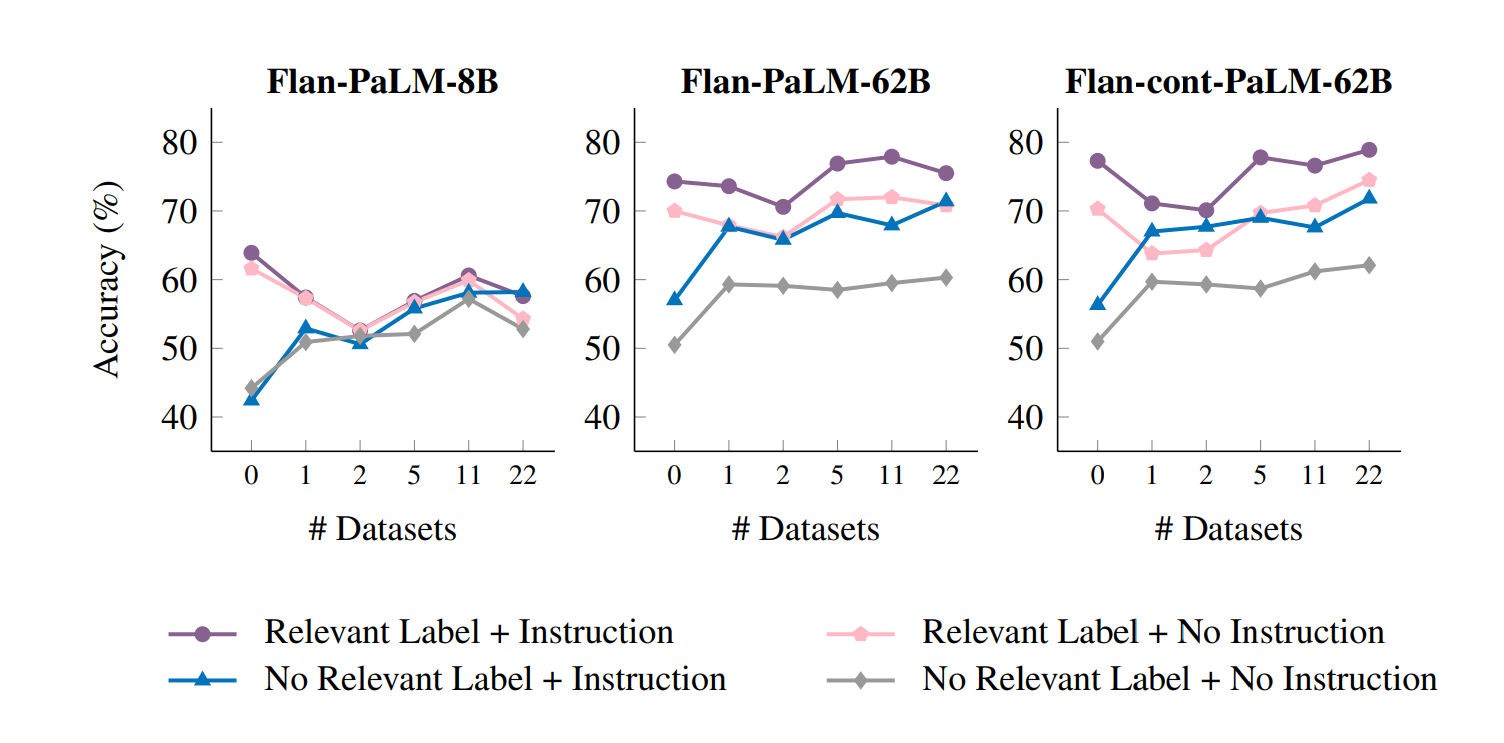
- チューニングステップ数
-
議論
- 言語モデルは基本的に丸暗記ベースで(アルゴリズムとか数学の問題とかに対しても)答えている節があって、その中で意味のない記号を用いた学習でアルゴリズム能力が上がったというのは興味深い
- ある種の高レベルなパターン認識とかできるようになったら面白いね
*****
Non sunt multiplicanda entia sine necessitate
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025