Vision Transformers Need Registers
reading papers
-
どんなものか
- 教師ありViTと自己教師ありViTを用いて特徴マップにおけるアーチファクトを同定する
- 推論中の画像の背景領域に高いAttentionが現れることがある
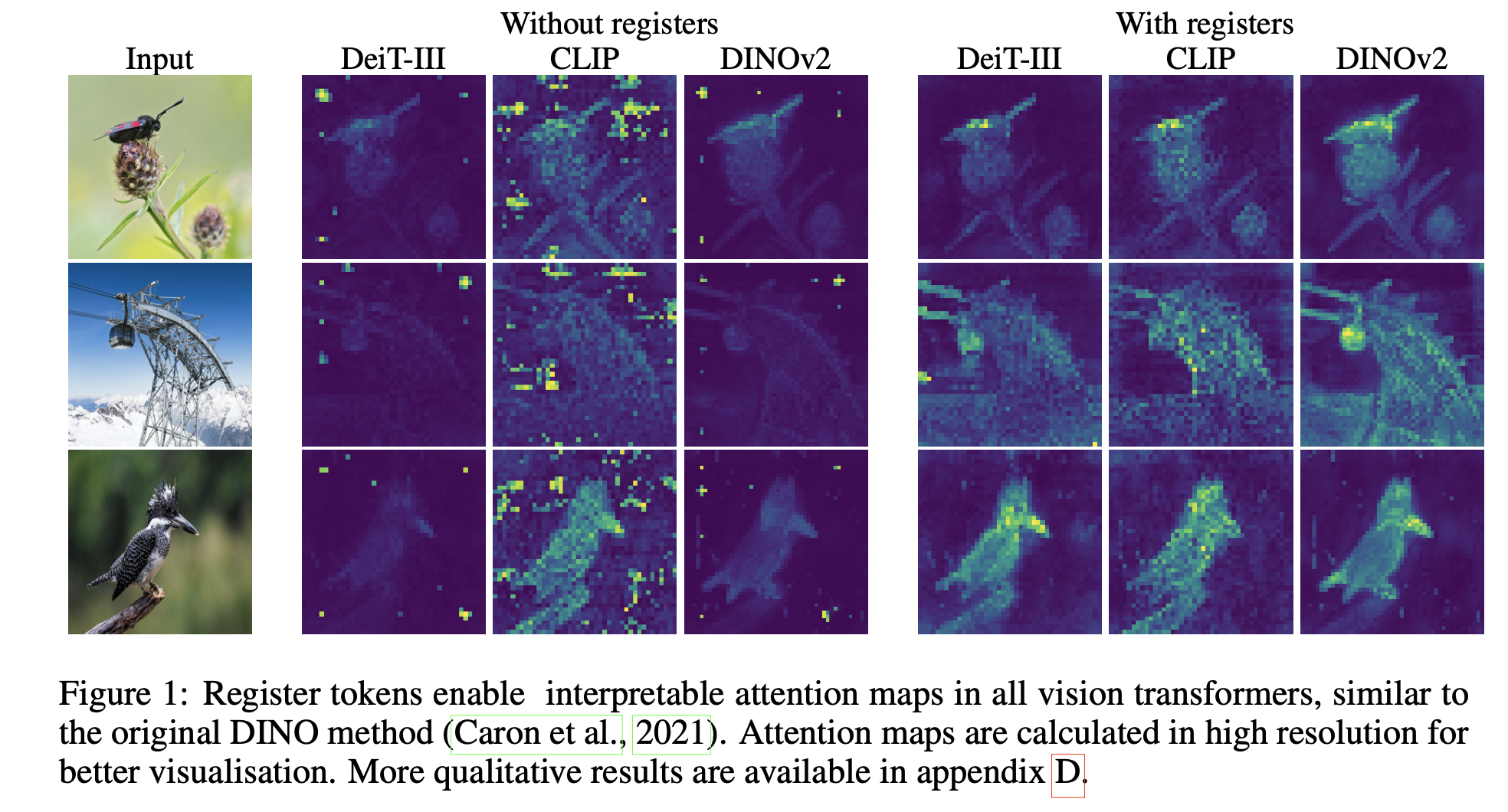
- Transformerの入力シーケンスに追加トークンを入れることで解決する
- 下流の視覚処理のためのより滑らかな特徴マップとアテンションマップに繋がることを示す
-
先行研究と比べて
- 自己教師あり学習手法の1つであるDINOに対してAttentionを解析したところ背景トークンのいくつかにAttentionが集まっていることがわかった
- このトークンから線形層を用いると他のトークンよりも画像分類など大域的な特徴を捉えられていることがわかった

-
技術や手法のポイント
- DINOの解析
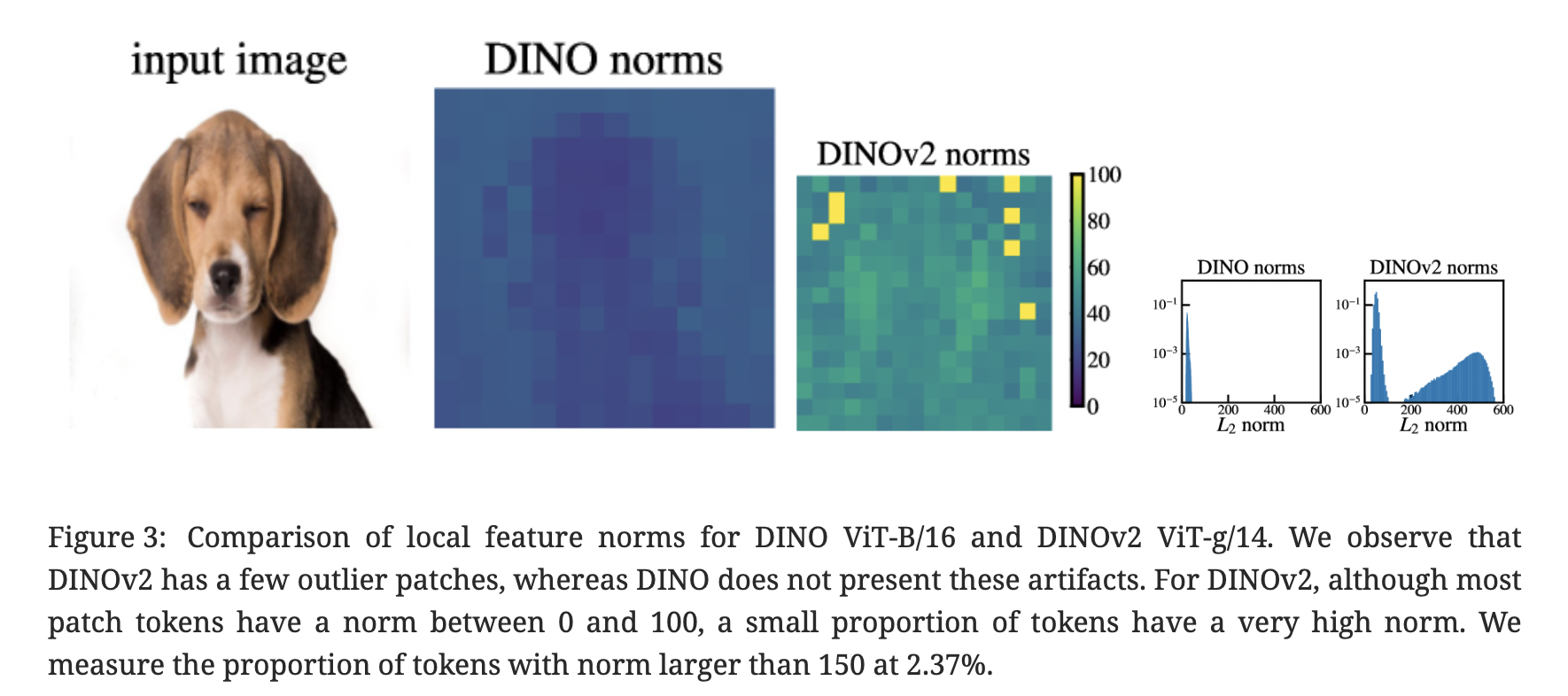
- 背景に一部集まる高ノルムの”アーティファクトトークン”は他のトークンと比べてノルムが極端に高い
- またアーティファクトトークンは画像の背景部分などパッチ情報が冗長なところに現れる
- 具体的には隣接パッチと非常によく似たパッチ上に現れる
- このアーティファクトトークンを元に学習可能な全結合層を用いて位置予測(画像のどこのパッチにあったかを予測)と、ピクセル再構成を行った
- アーティファクトトークンは、他のトークンに比べて精度が低く局所情報を持たないことがわかった
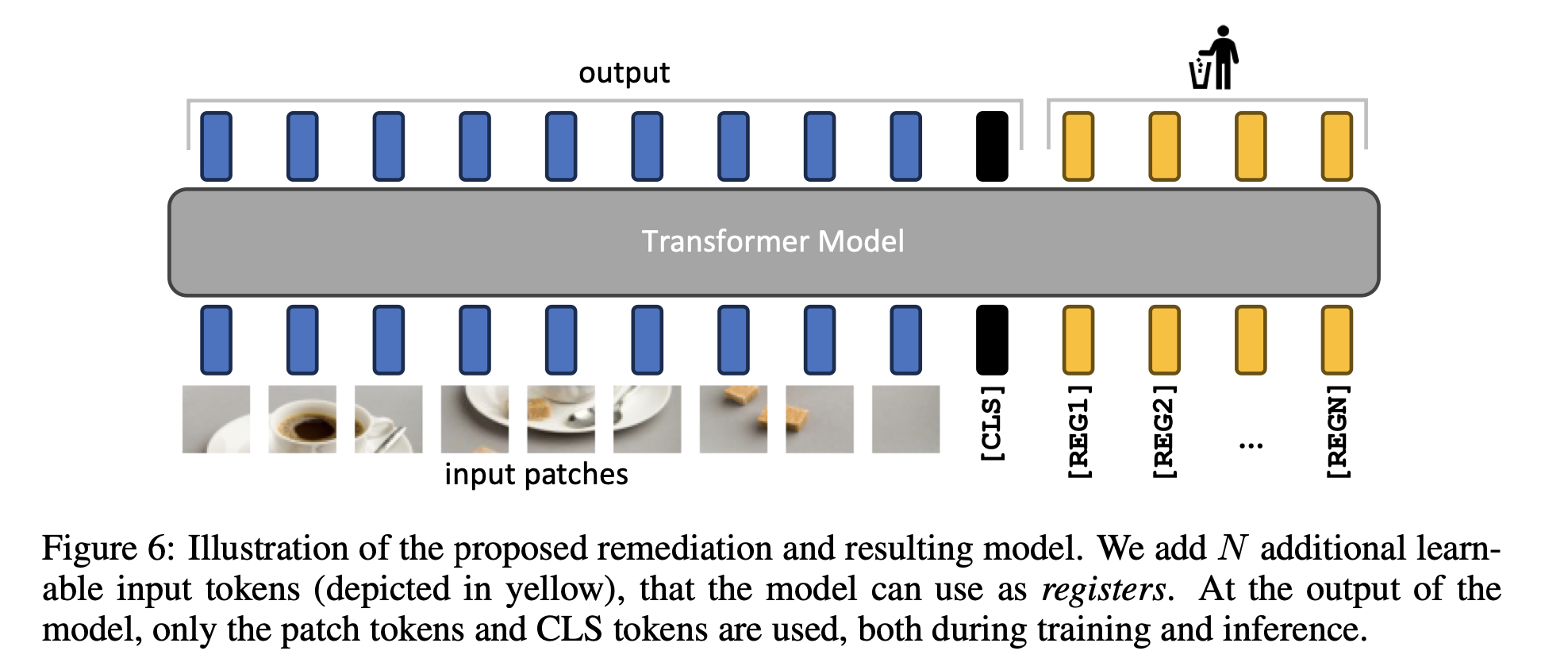
- 提案手法
- モデルがregisterとして使用することができる余分なトークンを明示的に追加する
-
検証方法
- モデルとしてDEIT-Ⅲ、OpenCLIP、DINOv2を用いてregisterの追加の効果を調べた
- 図(上のどんなものかに使われている図)に示すようにアーティファクトを取り除くことができる
- resiter tokenの数
- 他の実験では4を使用した

- 教師なし物体検出
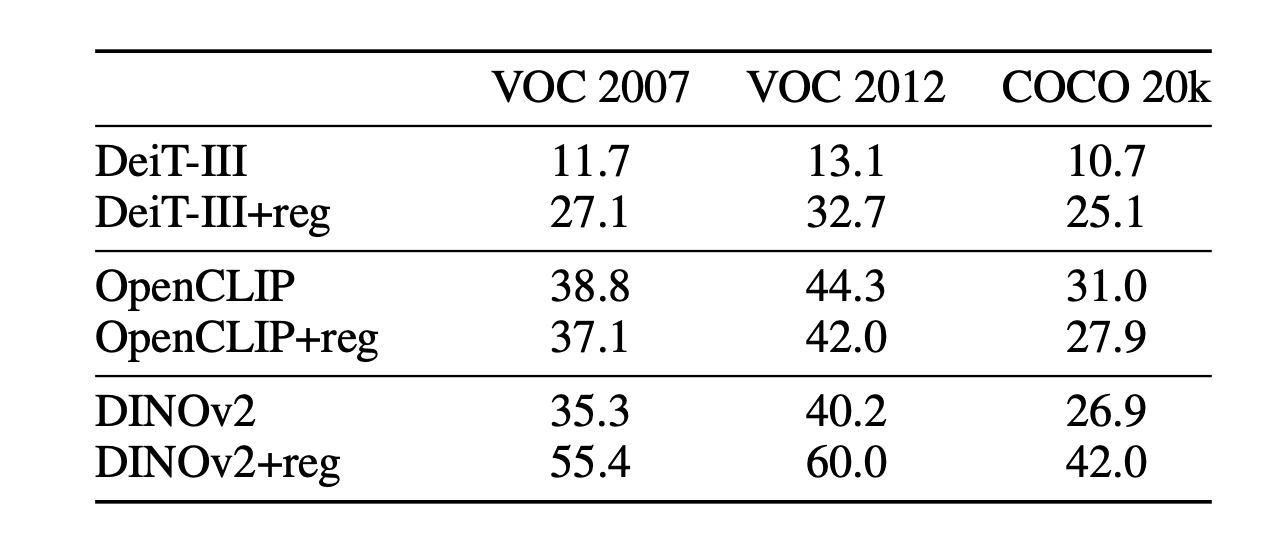
- 教師なし物体検出の精度が高い
-
議論
- 非常にシンプルな手法なので応用先が広そう
*****
Non sunt multiplicanda entia sine necessitate
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025