Learning to Model the World with Language
reading papers
-
どんなものか
- 将来の行動や報酬を予測するため、テキストや画像表現を使ったマルチモーダルなWorld Modelを学習し得られたWorld Modelから行動を学習するDynalangエージェントを紹介する
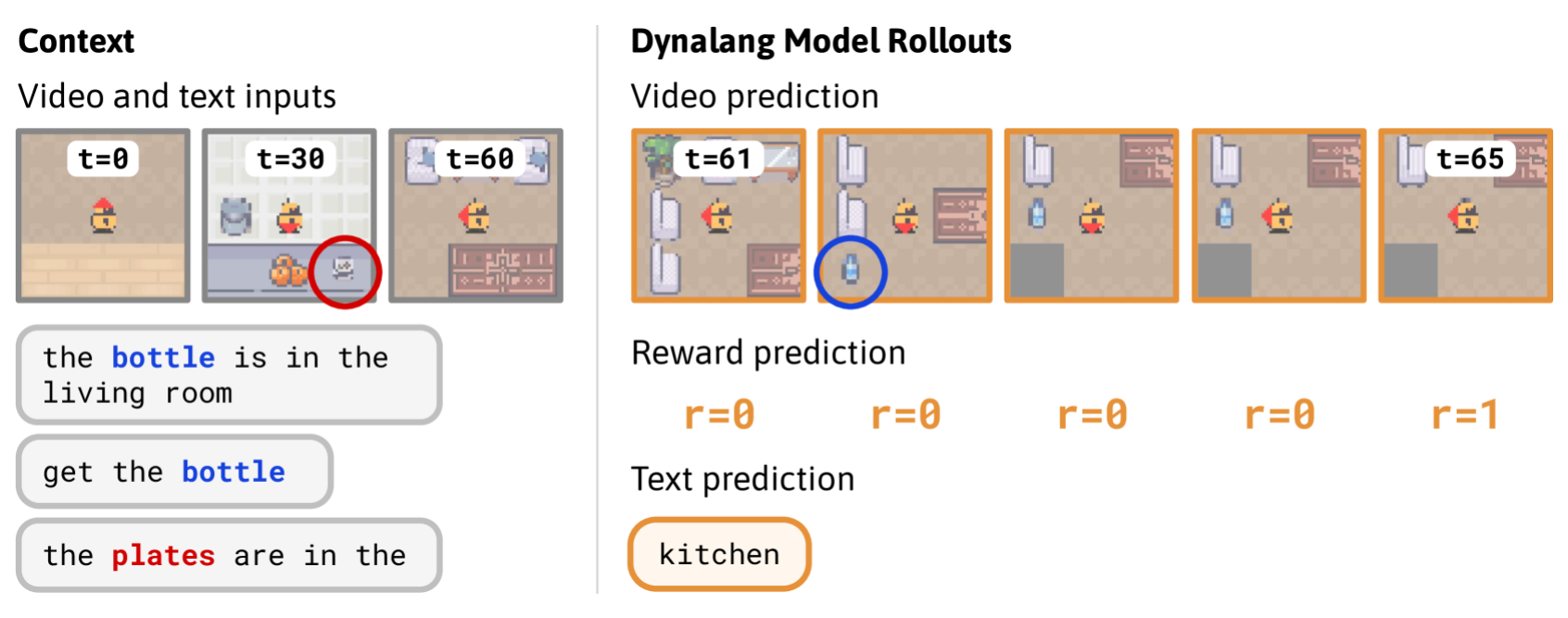
- “HomeGrid”環境における実際のモデルの予測。エージェントが環境からビデオと言語観測を受け取りながら様々な部屋を探索した。ボトルはリビングルームにあるという過去のテキストからエージェントはリビングルームの最終コーナーにボトルがあると予測。タスクを記述するテキスト「ボトルを取得しろ」からボトルを拾うと報酬が貰えると予測。
-
先行研究と比べて
- LLMと強化学習エージェントの先行研究の多くはタスクを解決するために直接言語を利用するように教えることに焦点を当てている
- しかし世界の仕組みの記述などより広範な種類の言語を使用する学習に取り組んだ研究は少ない
-
技術や手法のポイント
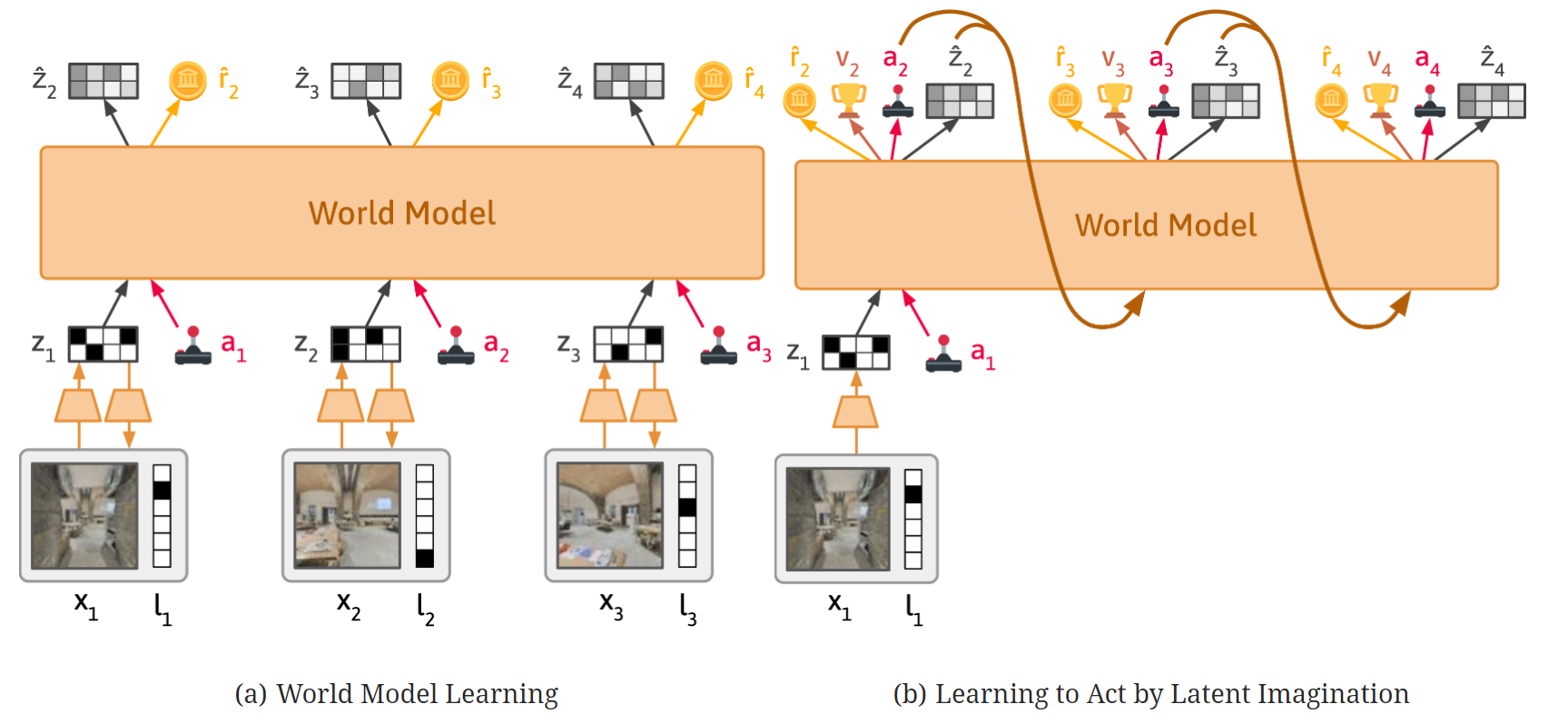
- a
- 画像フレームとテキストを観測として、それらを潜在表現に圧縮する
- モデルは次の表現を予測し表現から観測を再構成するように学習する
- b
- 方策の学習ではDreamerV3の学習アルゴリズムを用いて、World Modelから予測された報酬を最大化させるように学習をおこなう
- a
- NNモデル
- 画像エンコーダ:CNN
- テキスト埋め込み:MLPによる学習と、T5エンコーダで比較
-
検証方法
- HomeGrid環境
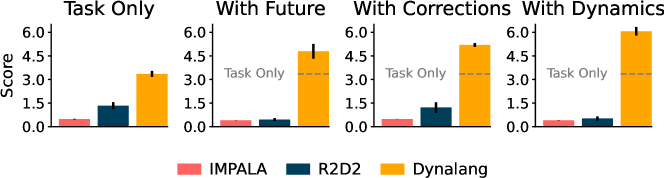
- 50Mステップ後のHomeGridのスコア。Dynalangはあらゆる種類の言語ヒントを使うことを学習し、タスク情報のみを与えられた予期よりも高いスコアを達成している。
-
議論
- 深層学習モデル部分についての詳細がもっと欲しかったかも
- モデル構造だったりの影響は少ないかもしれないけども
- この手の論文実装して実際に動かしてみないとなんも分からなさそう
*****
Non sunt multiplicanda entia sine necessitate
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025