GROOT: Learning to Follow Instructions by Watching Gameplay Videos
reading papers
-
どんなものか
- オープンワールド環境(minecraftなど)において、コストの高いテキストゲームプレイアノテーションを使わずにオープンエンドな指示に従うエージェントを学習させるフレームワークを提案する
- Causal Transformerに基づくエンコーダデコーダアーキテクチャで実装
-
先行研究と比べて
- minecraftでエージェントを作る研究は近年増えてきている
- インターネットスケールの動画を事前学習に用いたVPTではRLでfinetuningすることでダイヤモンド獲得に至ったが命令入力をサポートしていない
- VPTとMineCLIPを橋渡しすることでオープンエンドタスクを解決できるエージェントが作成されたが目標空間が十分でなく多段階タスクの解決が不十分
-
技術や手法のポイント
- ゲームプレイ動画から学習することを考える
- すなわちunknown policyにより集められた状態遷移 ${ s^{(i)}_{0:T} }_i$ から学習を行う
- 学習は過去の状態遷移が与えられた時に将来の状態の予測を行う形で学習する
- モデル
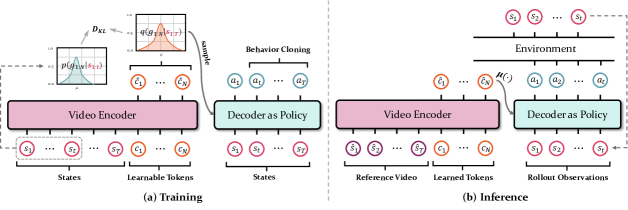 -
-
-
検証方法
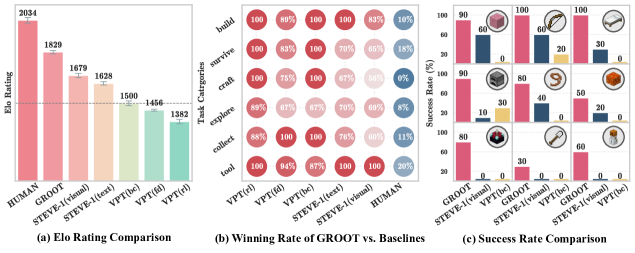
- a: 他の手法との比較Elo Rating比較
- b: 他の手法との勝率比較
- c: タスクごとの成功率

- ダイヤモンド獲得タスクの遷移
-
議論
- 実装してからという感じ
- VPTとMineCLIPを橋渡しすることでオープンエンドタスクを解決できるエージェントが作成されたが目標空間が十分でなく多段階タスクの解決が不十分
- てかこれはどうやって解決してたんや?
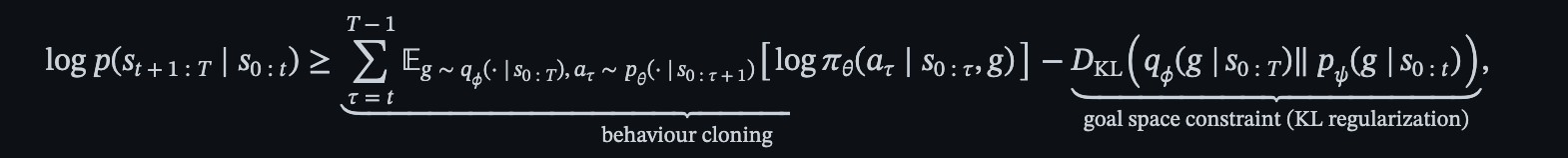
*****
Non sunt multiplicanda entia sine necessitate
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025