Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos
reading papers
-
どんなものか
- インターネット規模の逐次的な意思決定領域タスク(ロボット、ビデオゲーム)に対して半教師付き模倣学習を行う
- 少量のラベル付けされたデータでラベル付けされていない膨大なオンラインデータををラベル付けし学習できることを示す
-
先行研究と比べて
- 半教師付き模倣学習のほとんどの先行研究では比較的簡単なタスクを用いて行われていた
- 対して本研究ではマインクラフトというはるかに複雑でオープンエンドな環境で実験を行う
-
技術や手法のポイント
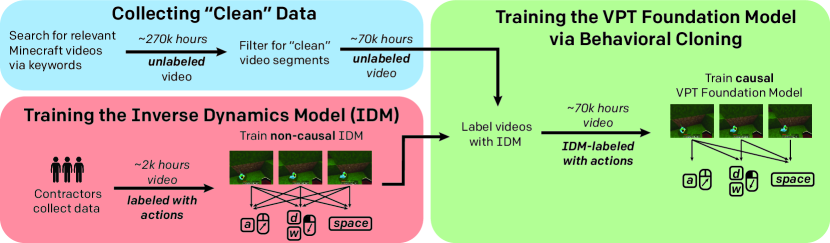
- Inverse Dynamics Models (IDM)
-
少量の教師付きラベルから、教師無しデータに対してラベルを付けるモデル $p_{\text{IDM}}(a_t o_{1 \ldots T})$ - 行動クローニングに比べ環境のダイナミクスのみを学習対照としておりデータ効率もよく学習が比較的容易である
- IDMでは将来のフレームからもどの行動がなされたかを使えるため
- ラベル付きデータ100時間程度分からかなり正確なIDMを学習できる
-
- Data Filtering
- 関連するキーワードで検索しウェブスケールの大量の動画を収集する
- ビジュアルアーティファクトを含まずサバイバルモードのデータをクリーンと呼び大量の動画からクリーンなもののみをdataとして使う
- ビジュアルアーティファクトはオーバレイされたプレイヤーの顔などを指す
-
検証方法
- IDM

- データサイズに対するIDMのaccuracyとIDMのデータ効率の良さを表すグラフ

- 左、web_cleanデータセットに対する訓練、検証損失と真ラベルを持つがIDMには使われてないデータに対する誤差
- 右、60分生存タスクにおいて何をどれくらい採掘したか
- ダイヤモンドタスク
- 強化学習でfine tuningすることで行う
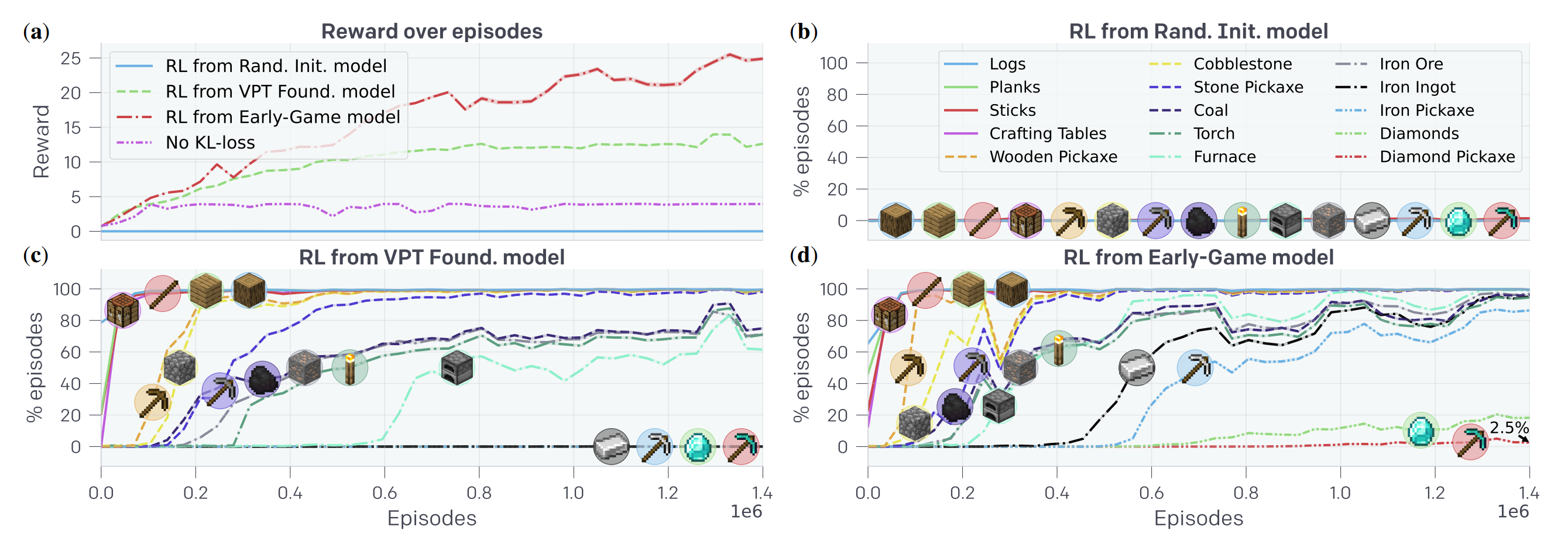
- ダイヤモンドを得るまでの遷移
-
議論
- OpenAIっぽい研究(OpenAIの研究です)
- 強化学習のためのよい巨大事前学習モデルになれそう
*****
Non sunt multiplicanda entia sine necessitate
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025