-
どんなものか
- 将来の行動や報酬を予測するため、テキストや画像表現を使ったマルチモーダルなWorld Modelを学習し得られたWorld Modelから行動を学習するDynalangエージェントを紹介する
Blog
tech diary
Learning to Model the World with Language
category: papers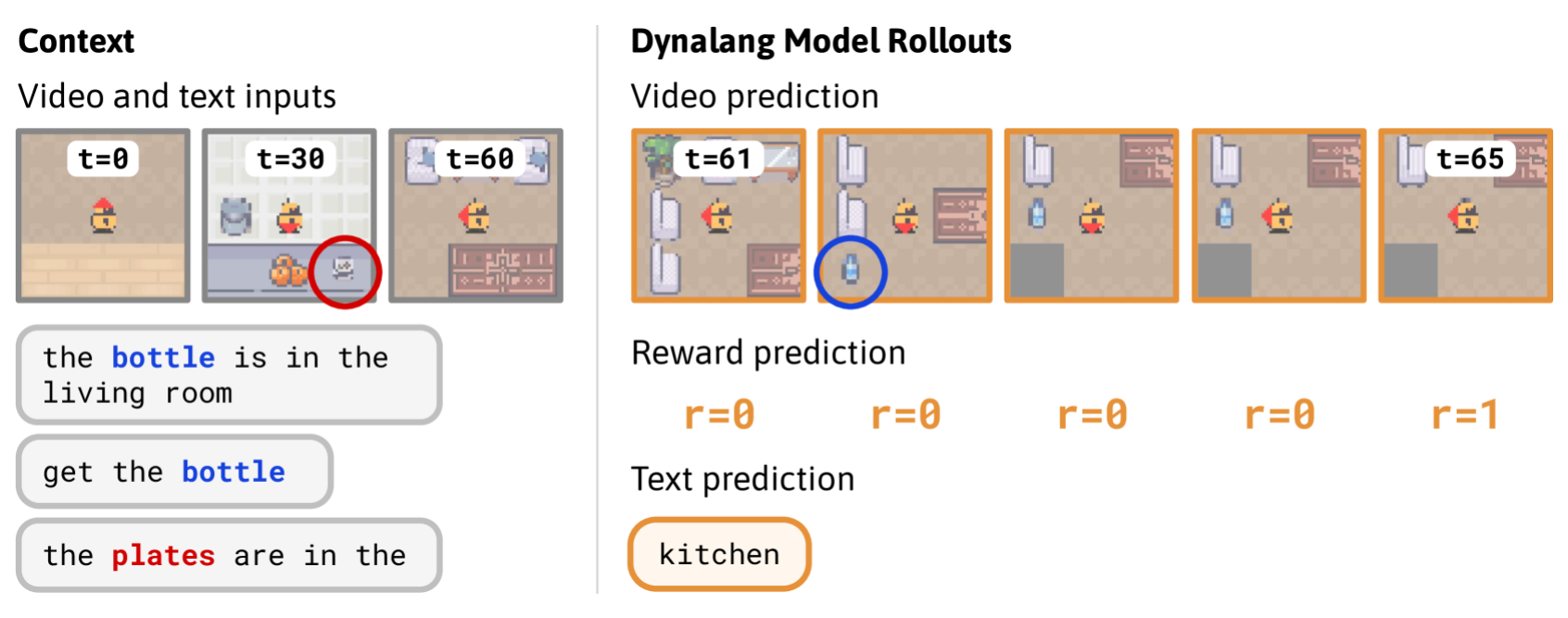
Vision Transformers Need Registers
category: papers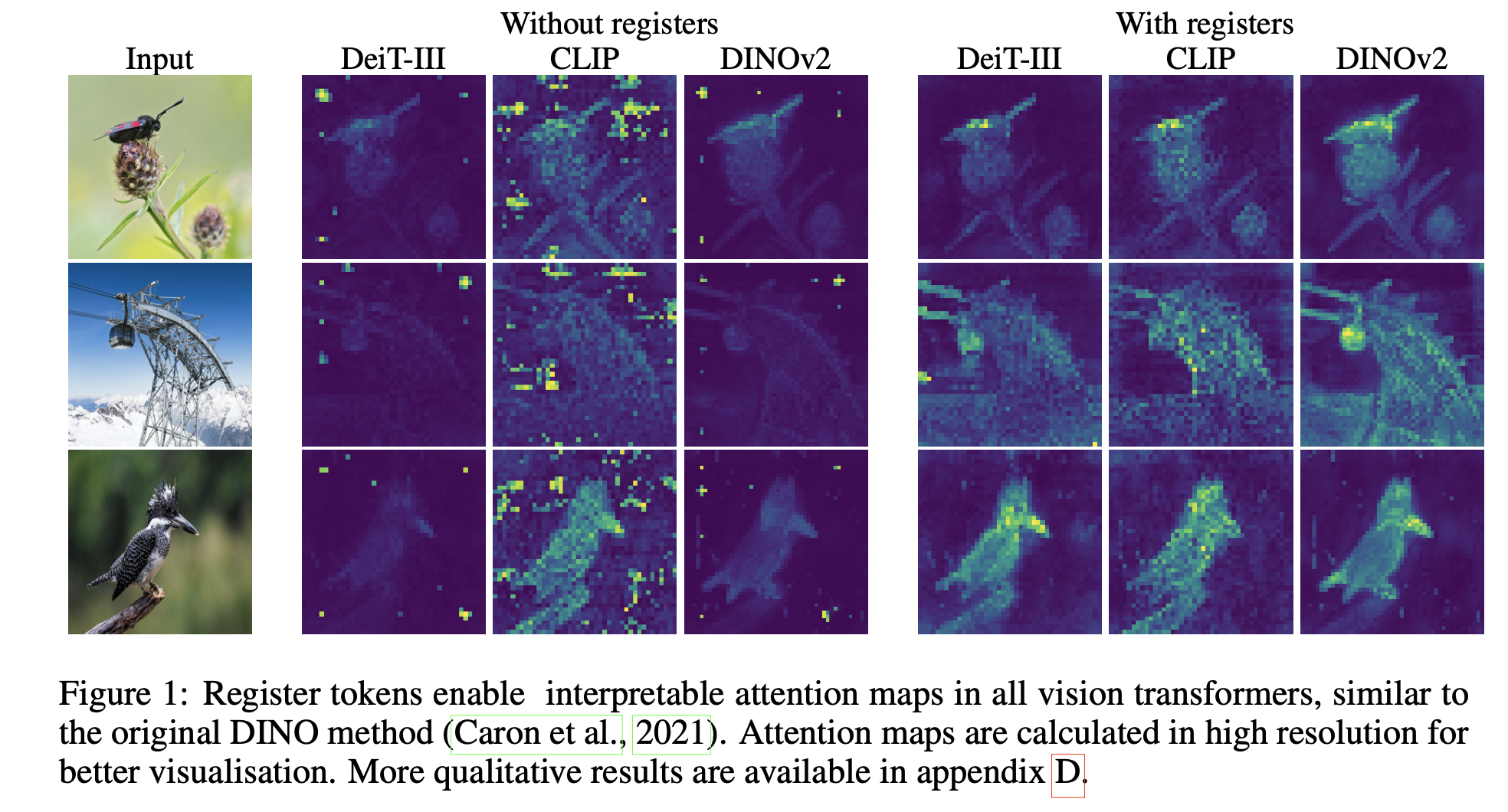
-
どんなものか
- 教師ありViTと自己教師ありViTを用いて特徴マップにおけるアーチファクトを同定する
- 推論中の画像の背景領域に高いAttentionが現れることがある
- Transformerの入力シーケンスに追加トークンを入れることで解決する
- 下流の視覚処理のためのより滑らかな特徴マップとアテンションマップに繋がることを示す
Symbol tuning improves in-context learning in language models
category: papers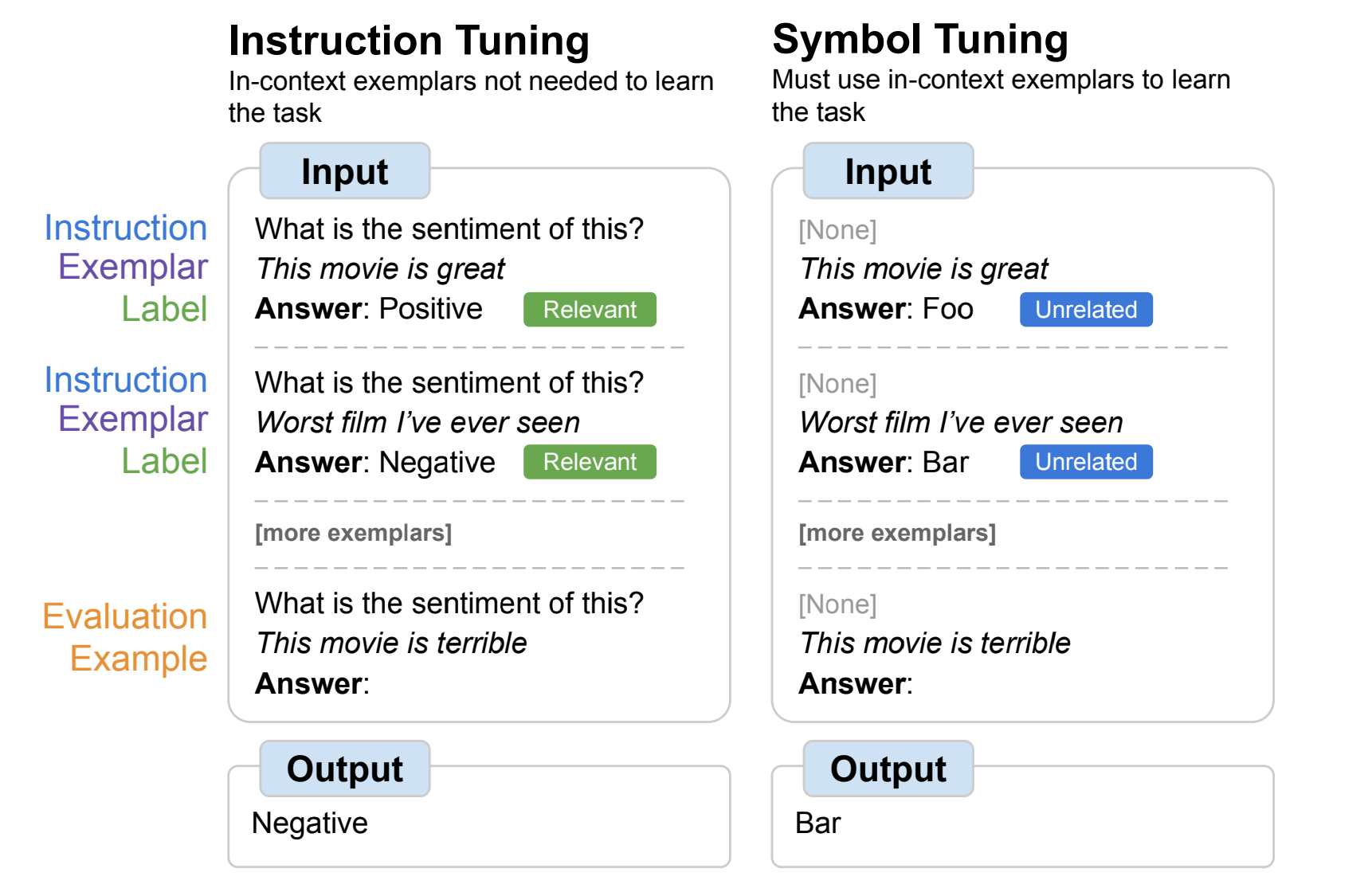
-
どんなものか
- 自然言語ラベルを任意の記号(例えば「foo/bar」)に置き換えてファインチューニングを行った
- symbol tuningはモデルがタスクを理解するために指示や自然言語ラベルを使用できないので入力とラベルのマッピング(in-context learning)を半強制させる
multitask prompted training enables zero-shot task generalization
category: papers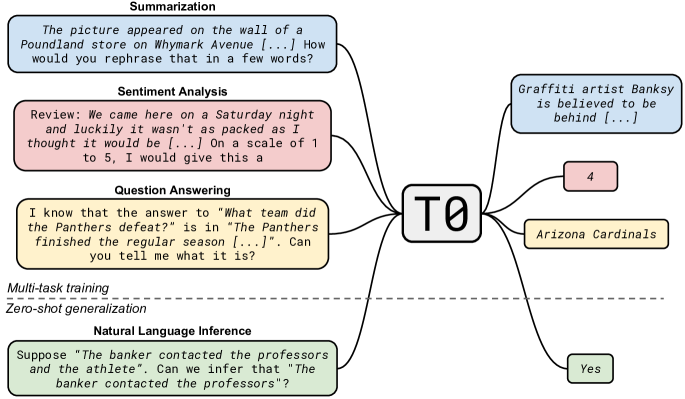
-
どんなものか
- 近年の大規模言語モデル(LLM)が多様なタスクにおいてゼロショット汎化性能が高いことが示されている。
- このゼロショット汎化性能が暗黙的なマルチタスク学習の結果によってもたらされていることを示した。
Retrieval-Augmented Multimodal Language Modeling
category: papers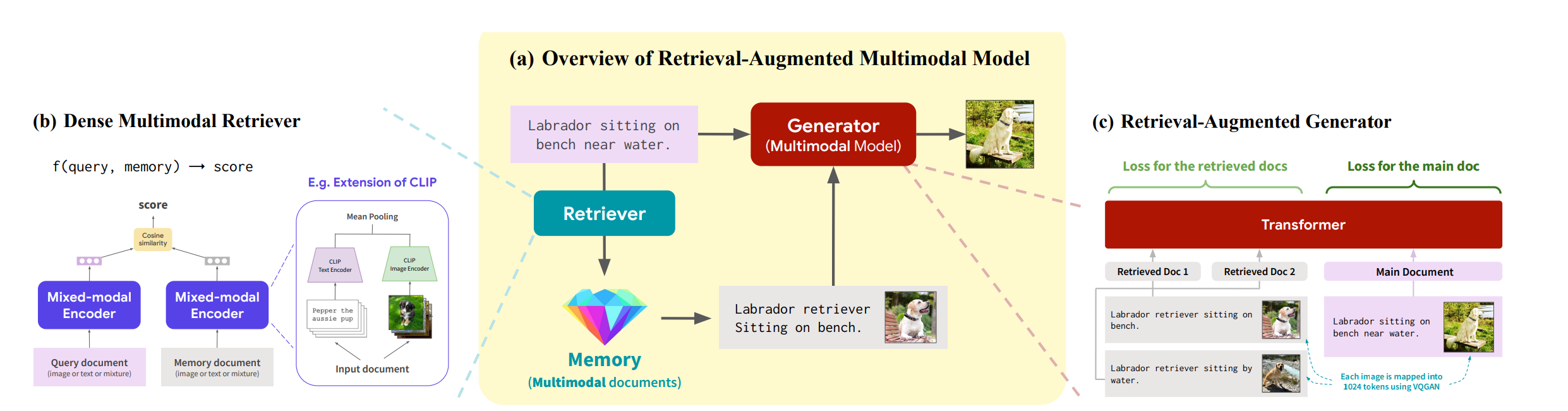
-
どんなものか
- Retrieverによって外部メモリ(例えばウェブ上の文書)を参照できるようにしたマルチモーダルモデルを提案した
- 大規模モデルでは全てをモデルパラメータに格納するため多くの知識のためによりデカいモデル、データセットが必要になってしまうため軽くしたいモチベーションがある
*****
Non sunt multiplicanda entia sine necessitate
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025
Pudhina is a free Jekyll theme by Knhash.
copyright ©️ 2022 - 2025